



AI Expansion - Supply Chain Analysis For CoWoS And HBM
28 Upstream Suppliers Analyzed For Generative AI Torque



AI is booming. Everyone wants more AI accelerators, and the primary limiting factor is the CoWoS advanced packaging to put the 5nm ASICs and HBM together. This lack of capacity is creating GPU shortages that will last through Q2 next year. In our prior report, we discussed how much CoWoS capacity big customers such as Nvidia, Broadcom, AMD, Marvell, Amazon/Alchip are asking TSMC to add. We also explained the end market use cases, allocation of CoWoS capacity, and the demand side of CoWoS.

Today we will discuss the supply side. TSMC is making rush orders to equipment makers to fill out its new Advanced Packaging fab in Zhunan. Samsung, Intel, Amkor, JCET, and ASE are also expanding some of their competing technologies for a bite of the generative AI pie. With some general purpose datacenter spending cannibalized by generative AI spending, such as memory and CPUs, understanding what is still growing is critical for understanding the supply chain. In this piece, we will detail the manufacturing process flow for CoWoS and 28 different upstream firms required for CoWoS & HBM production.
We will share which of these 28 upstream vendors have relatively large orders from this trend. We will also share which of these 28 suppliers are not receiving relatively large orders despite having their tools as part of the process flow. Some of our reporting is contradictory to what the market incorrectly believes. We will also reveal some innovations in the HBM3 and HBM4 process flow and a company that is getting completely displaced from the process flow as a result. Lastly, we want to share some updates on Nvidia’s quest to get more capacity next year. As always, the technology background will be shared freely, and the takeaways and details relevant to the current capacity buildout and suppliers will be shared with subscribers.
To recap, CoWoS is a “2.5D” packaging technology from TSMC where multiple active silicon dies (the usual configuration is logic and HBM stacks) are integrated on a passive silicon interposer. The interposer acts as a communication layer for the active die on top. The interposer and active silicon are then attached to a substrate that contains the I/O to place on the system PCB. CoWoS is the most popular packaging technology for GPUs and AI accelerators, as it is the primary method to co-package HBM and logic to get the most performance for training and inferencing workloads.
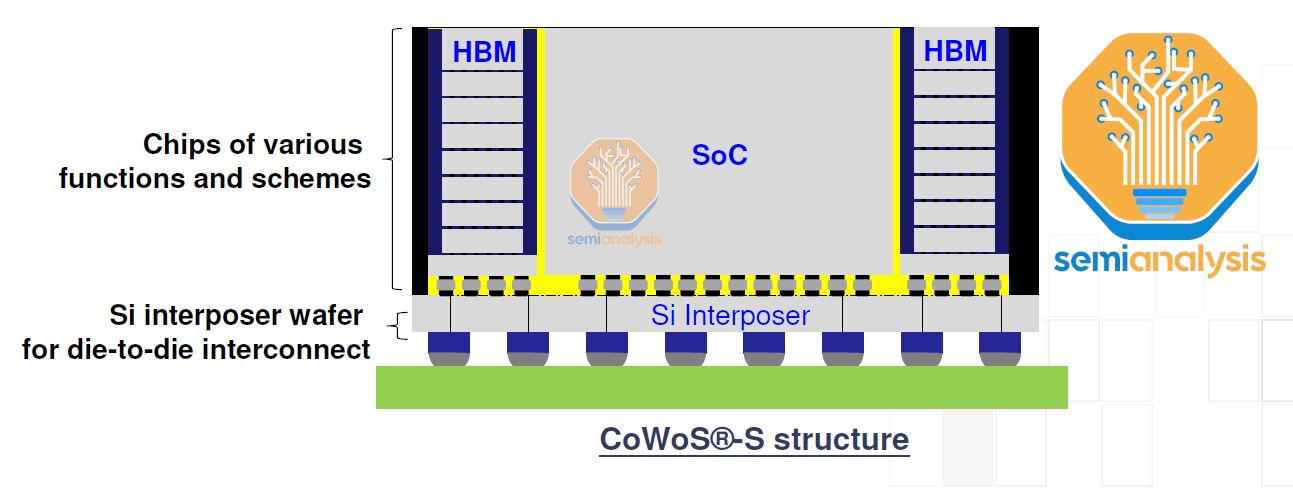
We will now detail the key manufacturing steps for CoWoS-S (the main variant).
Silicon Interposer Key Process Steps
The first part is fabricating the silicon interposer, which contains the “wires” connecting chips. The fabrication of this silicon interposer resembles traditional front-end wafer fabrication. It is often claimed that the silicon interposer is fabricated on a 65nm process technology, but that isn’t accurate. There are no transistors in the CoWoS interposer, only metal layers, which could be argued to resemble the metal layer pitches, but not really.
This is why 2.5D packaging is typically done in-house by the leading-edge foundry players, as they can produce the silicon interposer while also having direct access to the leading-edge silicon. While other OSATs such as ASE and Amkor have done advanced packaging similar to CoWoS or alternatives such as FOEB, they must source the silicon interposer/bridge from a foundry like UMC.
The fabrication of a silicon interposer starts with taking a blank silicon wafer and producing through silicon vias (TSVs). These TSVs pass through the wafer to provide vertical electrical connections that enable communication between the active silicon (logic and HBM) die on the topside of the interposer and the PCB substrate on the bottom of the package. These TSVs are how the chips send I/O to the outside world and also how the chips receive power.
To form the TSVs, the wafer is coated with photoresist and then patterned using photolithography. The TSV is then etched into the silicon by using a Deep Reactive Ion Etch (DRIE) to achieve a high aspect ratio etch. An insulation (SiOX, SiNx) and barrier layer (Ti or TA) is deposited using Chemical Vapor Deposition (CVD). Then a copper seed layer is deposited using Physical Vapor Deposition (PVD). The trench is then filled with copper using Electrochemical Deposition (ECD) to form the TSV. The vias do not pass through the whole wafer.

With the TSV fabrication completed, the Redistribution Layers (RDLs) are formed on the wafer's topside. Think of RDLs as multiple layers of wires to connect the various active chips together. Each RDL consists of a smaller via and actual RDL.
Silicon dioxide (SiO2) is deposited through PECVD, then photoresist is coated and using litho the RDL is patterned, then reactive ion etch is used to remove the Silicon Dioxide for the RDL via. This process is repeated multiple times to form the larger RDL layers on top.
In a typical recipe, Titanium and Copper is sputtered and the copper is deposited using electro-chemical deposition (ECD). However, we believe that TSMC uses extremely low-k dielectrics (perhaps SiCOH) to reduce capacitance rather than SiO2. The wafer is then removed of the excess plating metal using CMP. Mostly a standard dual damascene process. These steps are repeated for each additional RDL.

On the top RDL layer the under bump metallization (UBM) pads are formed by sputtering with copper. Photoresist is applied, exposed with photolithography to form the copper pillar patterns. The copper pillars are plated and then capped with solder. The photoresist is stripped and the excess UBM layer is etched away. The UBM and subsequent copper pillars are how the chips connect to silicon interposer.
Chip on Wafer Key Process Steps
Known good logic and HBM dies are now attached to the interposer wafer using a traditional flip-chip mass-reflow process. Flux is applied on the interposer. Flip chip bonders then place the die onto the interposer wafer’s pads. The wafer with all the die placed is then baked in a reflow oven, solidifying the connection between the bump solder and the pad. Excess flux residue is cleaned.
The gaps between the active die and the interposer are then filled with resin to protect the micro bumps from mechanical stress. The wafer is then baked again to cure the underfill.
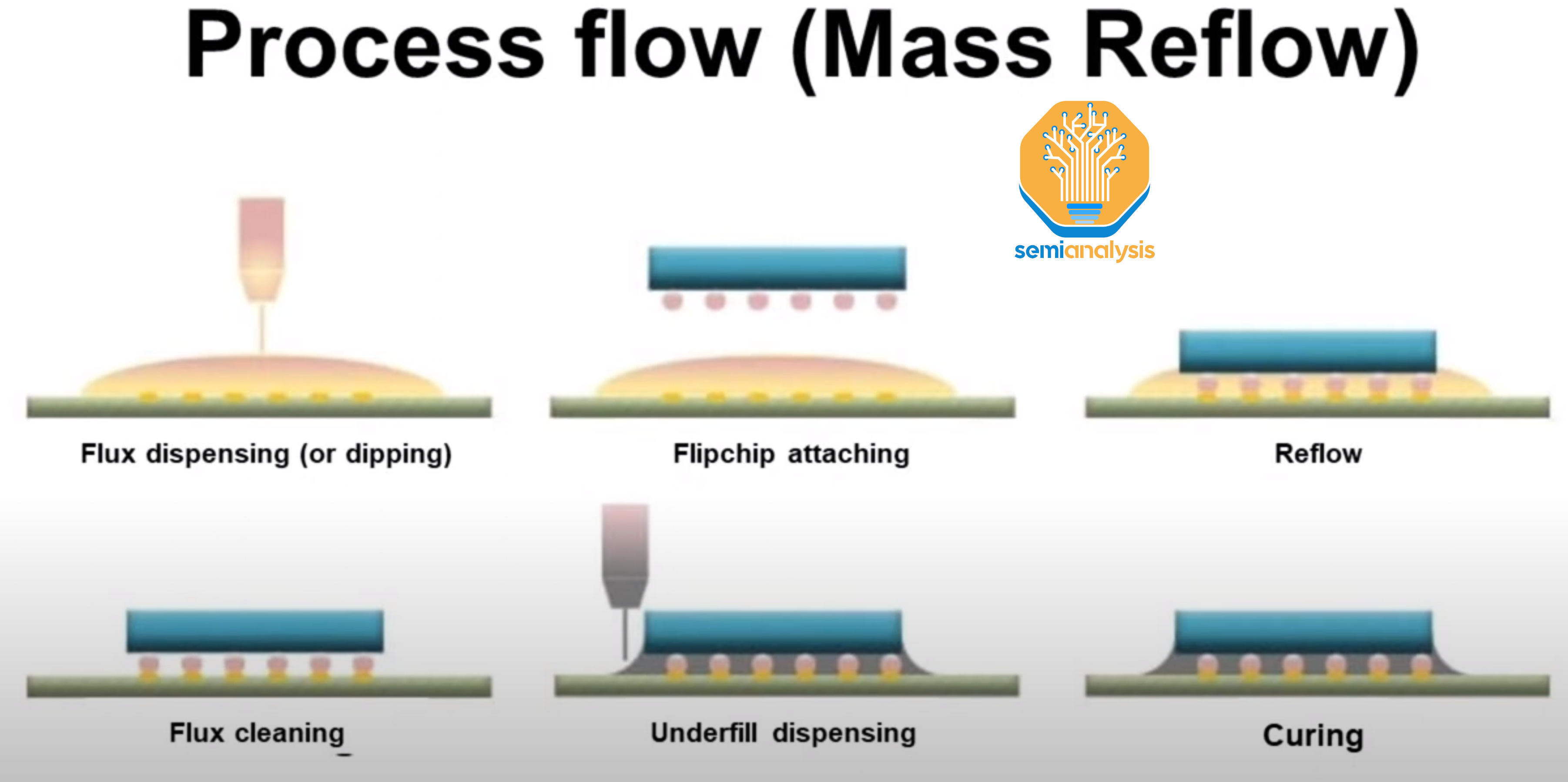
Next, the top dies are molded with resin to encapsulate them and CMP is used to smooth the surface and remove any excess resin. The molded interposer is now flipped and thinned by grinding and polishing down to around 100um in thickness to reveal the TSVs on the backside of the interposer.
The top die and encapsulation attached to the top of the interposer wafer may provide enough structural support and stability to the wafer despite being thinned down so a carrier wafer is not always required for support.
Wafer on Substrate Key Process Steps
The backside of the interposer is plated and bumped with C4 solder bumps and then diced into each individual package. Then each interposer die is attached using a flip chip again to the build-up package substrate to complete the package.
In the cross-section of Nvidia’s A100 below, we can see all the various elements of the CoWoS package.

At the top is the chip die with RDL and the copper pillar microbumps which are bonded to microbumps on the frontside of the silicon interposer. Then, there is the silicon interposer with the RDL on top. We can see the TSVs pass through the interposer with 2 TSVs per C4 bump below. At the bottom is the package substrate.
Note that the A100 only has a single side of RDL on the front side of the interposer. The A100 has a simpler architecture with only memory and GPU, so routing requirements are simpler. The MI300 consists of memory, CPUs, and GPUs all atop of AIDs, so this requires much more complex CoWoS routing, impacting cost and yield.
For subscribers, we will discuss 28 vendors who are involved in this process flow, the intensity of their steps, some of those 28 firms we believe will benefit massively. Most will not be impacted massively, but there are also some who we believe will not benefit in the way the broad market currently believes. We will also reveal innovations in the HBM3 and HBM4 bonding flow and a company that is getting displaced as a result.