





The rush to build out datacenters for AI training and inference has caused the markets to go crazy. For example, Credo (CRDO 0.00%↑) is up 27% in the last week, but they don’t benefit much. In the past, we exclusively explained how they lost their only AI socket. They also have 7 competitors in the AEC and ACC space. Vicor (VICR 0.00%↑) is up 30%. Over a year ago, we exclusively detailed Vicor lost their position as the supplier to the Nvidia H100. While Vicor has attempted to be designed back in, they are a very minor secondary option after Monolithic Power Systems (MPWR 0.00%↑).
There are many other firms that have rocketed up alongside Nvidia who don’t deserve to, and on the flip side of the coin, many firms have not been given the appropriate credit that they deserve.
IT budgets are limited. They can increase somewhat, but most likely Capex and Opex must be kept fixed at best for most enterprises given macroeconomic uncertainty. As such, the major boom in Nvidia sales comes directly from purchasing less non-GPU servers. The market has recognized traditional CPU sales will be weaker due to the AI spend shift. This is clearly shown off by Nvidia's revenue for datacenter being higher than Intel datacenter for the rest of the year.

Above is a demonstrative cost breakdown for a standard CPU only server. The typical CPU server will vary heavily, so do recognize this is only the loadout we viewed as high-performance, but also high volume. It has a total cost of around $10,424 for a large volume buyer, including ~$700 of margin for the original device maker. Memory is nearly 40% of the cost of the server with 512GB per socket, 1TB total. There are other bits and pieces of memory around the server, including on the NIC, BMC, management NIC, etc, but those are very insignificant to the total cost on the DRAM side. We did include those components in the BOM costs shared above and below.
NAND makes up 14.7% of the total BOM. Admittedly, many have moved towards networked storage, so this number is way higher than it should be for more modern architecture, but that’s more of a function of there being other servers with huge amounts of NAND and very little anything else. Memory as a whole is over half the cost of a classic server deployment. These costs ignore networking, which we covered in an earlier report.
In general, while there will still be many normal servers, the percentage of them will decrease for the AI era. The percentage of servers on units will be much lower, but on a dollar basis, the gap is massive. As datacenters move to accelerated computing, the cost allocated to various components shifts heavily. Nvidia sells DGX H100’s at around $270,000. The cost breakdown below includes Nvidia’s markup on the GPU + Switch baseboard and on the entire DGX server.
Separately, we also have a 8 GPU + 4 NVSwitch baseboard BOM cost breakdown between power delivery, memory, assembly, cooling, GPU cost, CoWoS cost, die cost, yield cost, HBM cost, etc. We will share that later.
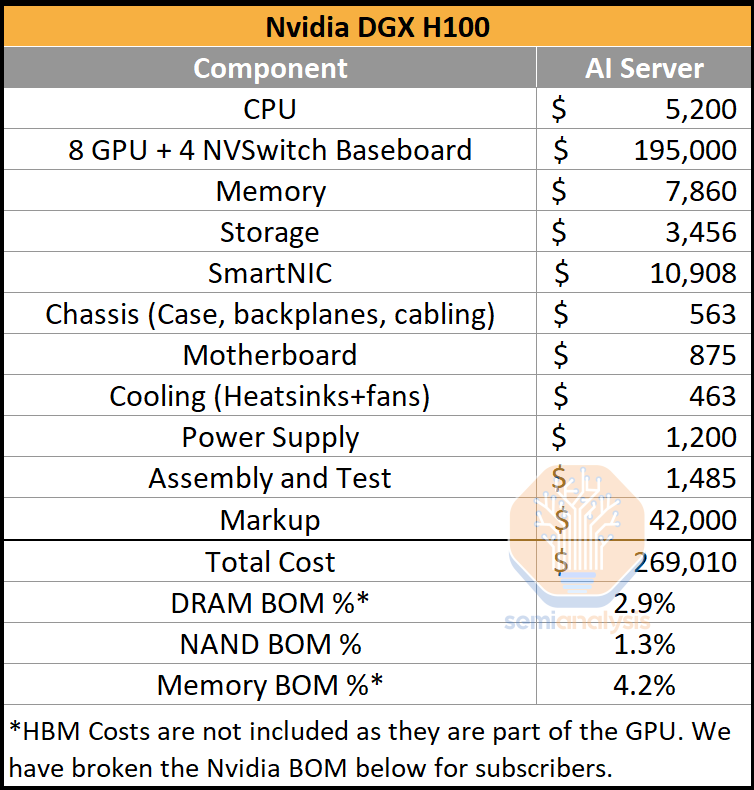
Nvidia’s gross profit per DGX H100 is almost $190,000. Of course, R&D and other operating expenses bring this much lower. Regardless, this mammoth margin comes with a big shift in memory cost as a percentage of servers, despite DDR5 memory per server growing to 2TB. There will be other CPU based and storage servers in the front-end network, but the AI servers themselves have less than 5% of their total cost allocated to memory when excluding HBM.
HBM costs are obviously very relevant, especially given Nvidia is currently single sourcing all their HBM3. We share these costs below for subscribers.