



Amazon Graviton 3 Uses Chiplets & Advanced Packaging To Commoditize High Performance CPUs | The First PCIe 5.0 And DDR5 Server CPU

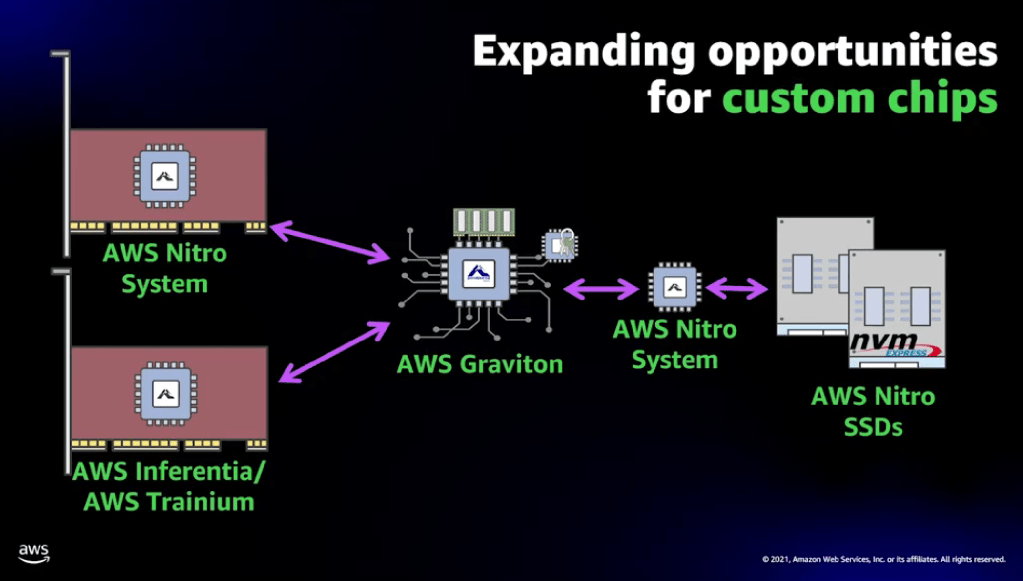
Amazon has shattered all norms continuously with their AWS platform. The hardware journey started with the acquisition on Annapurna Labs in 2015. Today Amazon announced Graviton3 and a custom SSD controller. The first impressive in-housing effort was with the AWS Nitro years back. Nitro extends from the custom hypervisor, a security chip, and the powerful Nitro networking cards. Amazon raced ahead of all SmartNIC and DPU efforts from merchant silicon providers and designed / implemented their own custom hardware stack. These NIC’s provide a huge security and operational efficiency advantage by allowing the separation of hypervisor and application layer.

Rather than having to dedicate CPU cores on each physical CPU to run the AWS management stack, Amazon can offload it onto their custom networking card. This frees up more cores to be rented directly to consumers per physical server. Amazon was able extract this as an operational advantage over other cloud service providers and keep margin away from the likes of Intel. Google is only starting to standardize this behavior across their cloud service stack. Google worked on partnership with Intel for a NIC called Mount Evans and are only now enabling behavior similar to Amazon’s Elastic Block Storage.
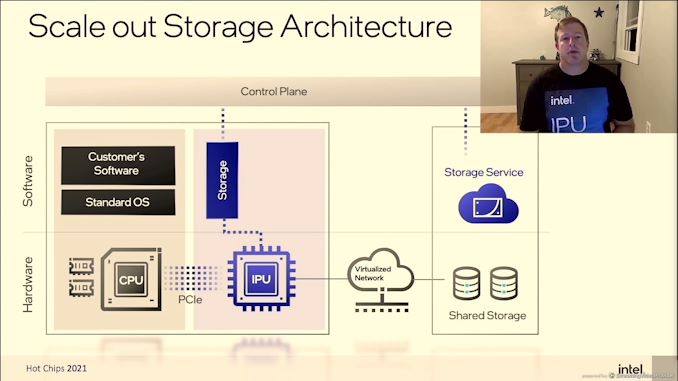
The operational advantage with scaling out storage is quite large. Rather than having to build out storage into each server, storage can be implemented in separate storage dedicated servers. This storage can then be virtually allocated to and provisioned it to various instances at run time. Clients functionally have no idea their storage is in a separate server, and AWS gets to utilize all storage more effectively. AWS can offer more flexibility on storage size size with various instance types as well. There is no overprovisioning of storage per physical server and it can more easily be managed in large dedicated pools. The configuration choices here are much more detailed and varied, but that’s for another day.
That brings us to todays announcements where Amazon announced a custom SSD controller and the Graviton3 CPU. Just because we like to tease, we will touch on the custom SSD controller first. Amazon receives a huge benefit in performance variation and cost by moving to a custom SSD controller. Cost is obvious; they now purchase raw NAND and get it packaged together with their controllers. AWS maintains control over their own supply chain and not be succumb to the highly variable controller ecosystem. SSD OEM margins are now in-house. AWS can also standardize controllers and performance characteristics across their datacenters.

The SSD’s controller maps data to a physical address on NAND chips. This abstraction is called the flash translation layer (FTL). The SSD controller needs to manage garbage collection, trim, and wear leveling of the SSD in order to maintain peak performance and maximum longevity. Some of these tasks impact performance. Amazon is taking this into their own hands by abstracting this management into software that they can control and update. The increased level of control allows Amazon to reduce performance variations. These management functions will no longer interfere with a customer's high performance storage demands. They can run seamlessly in the background without interfering with customer workloads.

Graviton3 is of course the star of the show. Amazon jumped forward as the first to many technologies on the server CPU side. They are using a chiplet design with 7 different dies. What stands out is that they are packaged using advanced packaging. The size of the micro-bumps connecting each die are <=55um whereas every CPU from Intel and AMD is still at >=100um. Intel and AMD only catch up with their next-generation CPUs. This enables a design where IO is disaggregated from the CPU without ballooning in power budget. AMD IO dies on Rome and Milan server CPUs take as much as 100W. This 100W eats into the power budget for the cores, and cannot be geared towards computations. Graviton achieves 50% higher memory bandwidth than AMD Milan and PCIe 5.0 connectivity while keeping the entire CPU power consumption in that same ~100W range.

The 64 cores are kept on a single monolithic die on a leading-edge process node while tiles for PCIe 5.0 and DDR5 are fabbed separately. This system design is partially the reason Amazon can deploy PCIe 5.0 and DDR5 ~6 months before Intel or AMD. Amazon is keeping costs down on the IP side by leveraging ARM’s stock cores and Synopsys / Cadence IP. While Amazon didn’t explicitly state the core type, SemiAnalysis can confirm that Amazon is using Arm’s Neoverse V1 core.
The 64-core compute die is ~282 mm², the 128b memory controller DDR5 die is ~21.7 mm², and the PCIe 5.0 controller die is ~43.6 mm².

The choice of this core is quite interesting. Most other hyperscalers are waiting for Neoverse N2, the follow on to Neoverse N1. Neoverse N1 is the core that shows up in Graviton2 and Ampere Altra. V1 had previously only racked up wins at the European, South Korean, and Indian domestic HPC efforts, so Amazon’s core choice here is quite interesting. Compared to N1 and N2, V1 is much wider. It offers double the FP execution units, but this comes at the cost of higher area. The change in core leads to performance increasing 25% in SPECint 2017 and 60% in SPECfp 2017. This huge increase in performance and the IO changes comes despite holding essentially the same power and clocks as Graviton2. Transistor counts only grew from 30B to 50B.

Amazon is taking a holistic system level approach are therefore they are focused on compute density. Rather than these massive packages with hundreds of watts in power consumption like AMD and Intel, Amazon is turning the opposite direction. They are stuffing 3 CPUs into an air-cooled server unit. Intel and AMD are approaching 350W-400W for the next generation CPU's, Amazon is targeting 1/3 to 1/4 this number. Amazon is maximizing the amount of performance on the rack level and minimizing cost. This is achieved in a couple ways.
Networking costs as a percentage of server costs are ballooning as we move to the 400G and 800G era. Running individual networking cards per CPU is cost prohibitive. Merchant silicon is usually run at 1 CPU and very occasionally, 2 CPUs per NIC. The ratio with Graviton3 is flipped to 3 CPU slaves per NIC.

Amazon also made the intelligent decision to package these processors as BGA. Merchant silicon vendors such as AMD and Intel use sockets. This decision add complexity and cost, another point of failure, and they decrease density of the CPU to motherboard connection which requires more motherboard space. Sockets are pretty much required for selling server CPUs, but Amazon can eschew this due to their vertical integration. BGA is a key reason Amazon why can shove 3 CPUs per server unit.
These CPUs are already deployed widely in production. Amazon has been using them for quite some time and some of their larger customers such as Epic Games, F1, Twitter, and Honeycomb already have them deployed in production as well. Traction for Graviton3 is huge, and the cost/$ advantage extends beyond just vertical integration. The system level choices that power Graviton3 lead to it being a winner for general CPU compute instances.
While x86 CPU vendors will maintain their peak performance per CPU lead, Intel and AMD are ignoring the more important battle. That battle is over total cost of ownership (TCO) per unit of compute on a server and rack level for generalized CPUs. Commoditization is here for the CPU market, and even if Intel's and AMD's individual core design is markedly better, it won't change the equation. Intel and AMD are hyper focusing on certain aspects, which make them miss crucial factors in system level design such as peak power being too high, density being too low, and clock speeds being pushed too far.
Graviton3 should be making Intel and AMD executive’s quiver. In fact, all merchant silicon vendors should be terrified because Microsoft, Facebook, Google, and the major Chinese players want to replicate this vertical integration across networking, CPU, SSD, AI inference, and AI training. This basket of hyperscale firms are growing much faster than rest of the market, and they are swallowing up computing dollars spent like veracious beasts. Tech monopolies are going vertical, and there doesn't seem to be much being done to stop this long term tsunami.
We have something very interesting about the packaging behind the paywall related to this CPU and a certain semiconductor company that is always on investors minds.