



AMD Genoa Detailed – Architecture Makes Xeon Look Like A Dinosaur
Twice the CPU without twice the power

This week we were fortunate enough to attend AMD’s 4th generation Genoa server launch event. For those more concerned about volumes, ASPs, and revenue, check out our deep dive report here.

This report will focus mostly on technology, architecture, performance, and SKUs. Long story short, the server industry has been slow to switch to new suppliers due to long validation cycle times. The safe bet was to stick to your existing vendor, whether it was IBM decades ago, or Intel now.
It is not safe to stay with the performance deficit of Xeon.
Ram Peddibhotla, Head of Epyc Product Management

The 4th generation Epyc Genoa launch marks the 3rd consecutive generation where AMD beats Intel in the majority performance metrics. Rome and Milan made the cloud players start buying a lot of AMD, and Genoa is when the volumes jump across most remaining markets and end users. SemiAnalysis believes the gap between Genoa and Sapphire Rapids is larger than the gap between Milan and Ice Lake. This gap will only continue widening until late 2024, but probably in 2025 with Sierra Forrest and Granite Rapids.

AMD is coming with more and more variants of their CPUs. While CPUs are for general-purpose workloads, there is increasing customization for various end markets. In the 4th generation, there are 4 variants. Genoa, the topic for today, is for general purpose and mainstream.
Bergamo is for cloud-native workloads. The IO die and platform are shared with Genoa, so many aspects are similar, but replacing the Zen 4 core for the Zen 4C core, which has the same core architecture and L2 cache with half the L3 cache per core. The cores for Zen 4C are laid out to maximize density at the cost of frequency.
Genoa will also have another variant called Genoa X is for “technical.” This is an odd definition, but it is for computational fluid dynamics, EDA, and other workloads requiring more cache. Genoa X will be Genoa but with 3D V-Cache, and potentially multiple variants.
Siena is for Telco and Edge. We would also say it’s for some enterprise deployments due to lower power and Capex demands. Siena can be thought of as 1/2 of Genoa or Bergamo from memory to core counts. Not exactly, but that’s the gist of it.
Lastly, AMD’s next generation is called Turin, which we expect to launch in the first half of 2024. It has even more families and variants, but it’s not fair to AMD to share some of those details today.

The summary is that AMD’s Genoa is ~2x the performance of Milan, with only a modest power consumption increase. Gains are larger in floating point thanks to the addition of AVX512 and the outsized memory bandwidth bump.

There are no major surprises with the specs. 96 cores, 12 channels of DDR5, and 160 PCIe Gen 5 lanes (64 of which are CXL capable). The CXL-attached memory encryption is critical to security in multi-tenant cloud architectures. We detailed these features in the past here. No support is required from the CXL memory ASIC/device to support encryption, and this is not dependent on any specific ASIC.

The heart of Genoa is the Zen 4 core. Performance is up massively with a 14% improvement in IPC, and markedly higher frequency and average latency is improved due to the 2x larger L2 size. When we pixel count the image on the right which says its only for illustrative purposes, Front End accounts for 40% of the IPC improvement, Load/Store improvements account for 24%, Branch Prediction accounts for 20%, and L2 Cache/Execution engine are 8% each.
We got to meet Mike Clark yesterday, and that was incredible. For those who don’t know, he is basically the inventor of Zen. He’s in charge of the entire CPU core roadmap, but he’s pretty humble.
I’m honored to represent the greatest CPU team on earth
Mike Clark, AMD Zen Chief Architect

We won’t get into the architecture too much as that was covered in much better detail by our friends over at Chips And Cheese.
AMD’s Zen 4 Part 1: Frontend and Execution Engine
AMD’s Zen 4, Part 2: Memory Subsystem and Conclusion
The one thing we do want to touch on is AVX512, a floating-point vector instruction library. Intel implements it at 512-bit wide, but that also means it is too costly in silicon area, and Intel doesn’t include the feature on client chips. Furthermore, when AVX512 is lit up, the clock speed of a chip falls, and the rest of the workloads on a chip suffer. AMD went a much more intelligent route by splitting it into multiple cycles across their 256-bit unit. This means there is no noisy neighbor problem, and the silicon area impact remains small.

Security is always important to mention, and there are multiple core and SOC level security features that AMD has advantages over Intel with. The most noteworthy one is related to SMT or hyperthreading. Ampere Computing likes to make the argument that running multiple threads per core is unsecure. AMD with SEV-SNP is answering that. Secure guest threads, if implementing this feature, can elect not to run when there is an active sibling thread on the shared core. This prevents side-channel attacks such as Spectre and Meltdown.

The IO Die is arguably a much larger and more important change with the 4th generation Epyc launch. It is built on an N6 process node rather than N5 like the CPU chiplet. The IO die is now beefed up to communicate with 12 chiplets through a much larger package that has more layers. When the slides have a ton of words, that means they are great because there is very little explanation needed; you can read them!
Another noteworthy point is that the socket is completely reworked. The mounting mechanism is more robust, and the pins have a much tighter 0.94 x 0.81mm pitch. The dimensions grew from 58mm x 75mm to 72mm x 75mm. The larger package with more layers is a big deal for companies like Unimicron
AMD’s scalability of IO is very noteworthy. They use combo-capable SerDes. In essence, these SerDes can have multiple personalities, making the options of what is connected very configurable. The platform can be configured with 3 or for Infinity fabric lanes, enabling scalable PCIe lane counts in a 2S configuration. Each 2S server can have either 3 Infinity fabric lanes and 160 PCIe Lanes with another 12 more PCIe links for the platform, or 4 IFIS, 128 PCIe, and 12 PCIe for the platform. Each 16x PCIe root complex can be cut down to 9 PCIe devices with 1 8x device + 8 1x devices.

Given Genoa massively increasing IO speeds, properly utilizing that bandwidth is critical. The enhanced AVIC reduces the overhead from virtualizing IO devices. This enables much higher bandwidth utilization rates and less CPU overhead. Milan had an earlier version, but it was more so prototyping. Now with Genoa, IO devices have near-native performance. The testing with Nvidia’s Mellanox Connect X7 running InfiniBand.

Genoa has key enhancements in memory cost, which is 50% of a server’s BOM, which cannot be understated.
The support for 72-bit and 80-bit DIMMs is noteworthy. Most servers will use 80-bit ECC, but some hyperscalers want to cut down to 72-bit. There are still some ECC capabilities relative to the 64-bit that non-ECC memory has, but less than the mission-critical 80-bit that is widely used. The advantage here is that there is 1 less DRAM die for parity checks. The “Bounded Fault” capability also assists with this because if errors are detected in the memory devices, these issues can be mapped.
The other important feature is dual rank versus single rank memory. With Milan and most Intel platforms, dual-rank memory is crucial to maximizing performance. There’s a 25% performance delta on Milan, for example. With Genoa, this is brought down to 4.5%. This is another considerable cost improvement because cheaper single-rank memory can be used.
Genoa has higher memory latency than Milan, 118ns on Genoa versus 105ns on Milan. AMD’s argument against this is that only 3ns of this is from the massively larger IO die, 73ns on Genoa versus 70ns on Milan. Most of the memory latency impact comes from the DDR5 memory device itself. 35ns on DDR5 versus 25ns on DDR4. This comes from looser timings due to DDR5 immaturity, larger bank sizes, and other changes in the architecture. The memory latency impact is large, but the tiny increase on SOC level is amazing.'

The IO Die to Core Complex Die connection has been improved massively. The power per bit transferred is down to below ~2pj/bit. For reference, EMIB is claimed to be ~0.5pj/bit. The most noteworthy aspect is that there is a new GMI3-Wide format. With Client Zen 4 and previous generations of Zen chiplets, there was 1 GMI link between the IOD and CCD. With Genoa, in the lower core count, lower CCD SKUs, multiple GMI links can be connected to the CCD. This is a massive increase in bandwidth available to the lower core count SKUs. Specifically, this will help the relational database and high-frequency SKUs where per-core licensing is a huge cost.
Power management is enhanced. Genoa has 2 basic modes for power management, performance determinism or power determinism. Due to thermal and silicon variation, there can be many differences between different workloads on different chips. Silicon is not deterministic, given that manufacturing involves thousands of process steps.
Performance determinism is for firms that want consistent performance. It consumes less power when allowed to, and performance is kept stable. Most customers will choose this option because stability is vital.
Power determinism is for keeping power consumption stable and ramping performance up and down. Given factors such as the silicon lottery, thermal budget, and workloads, the chip will ramp up and down clock speeds.
In addition to the power management modes, there is a configurable TDP for Genoa chips. The peak boost behavior will vary depending on which option is chosen. Clock boosting is based on reliability and peak power delivery. High-activity workloads will run at lower frequencies. System and silicon margin are considered.
Compared to consumer platforms, power budgets are not exceeded for a long duration. TDP can only be exceeded for 10s of milliseconds.

AMD generally supports CXL 1.1 but supports CXL 2.0 for Type 3 memory devices. We exclusively detailed this feature support level here.
Type 3 is what the ecosystem wanted.
Kevin Lepak, Genoa Server SOC Chief Architect
Genoa was delayed 2 quarters to add this feature, and we believe that was the correct decision.

One noteworthy item is that the 64 lanes of CXL can be bifurcated into 16 4x devices. As we detailed exclusively here, Sapphire Rapids is not capable of CXL lane bifurcation. If one connects a 4x or 8x CXL device, that will consume all 16 lanes. Emerald Rapids fixes that feature, but that is a year away.
Hypervisors cannot change the memory assignment under the guest, which is huge for users using CXL-attached memory in the cloud.
The pillars of performance for AMD are per-socket performance leadership, per-core performance leadership, leadership across all workloads and market segments, and leadership in TCO and sustainability. This is all bolstered by leadership energy efficiency.

This is shown best by this 1 comparison of a midrange Genoa chip competing against 2 top-end Xeons. AMD has higher performance, lower power, lower CPU cost, with fewer cores.

The lead AMD has is groundbreaking. The big thing to note is that when software per core licensing costs come into play, this lead extends even further in TCO. This is best shown in the enterprise benchmark, which runs VMMark. VMMark runs 19 representative VM per tile and then sees how many tiles can be run as well as the speed. Genoa is faster and can handle more VMs.
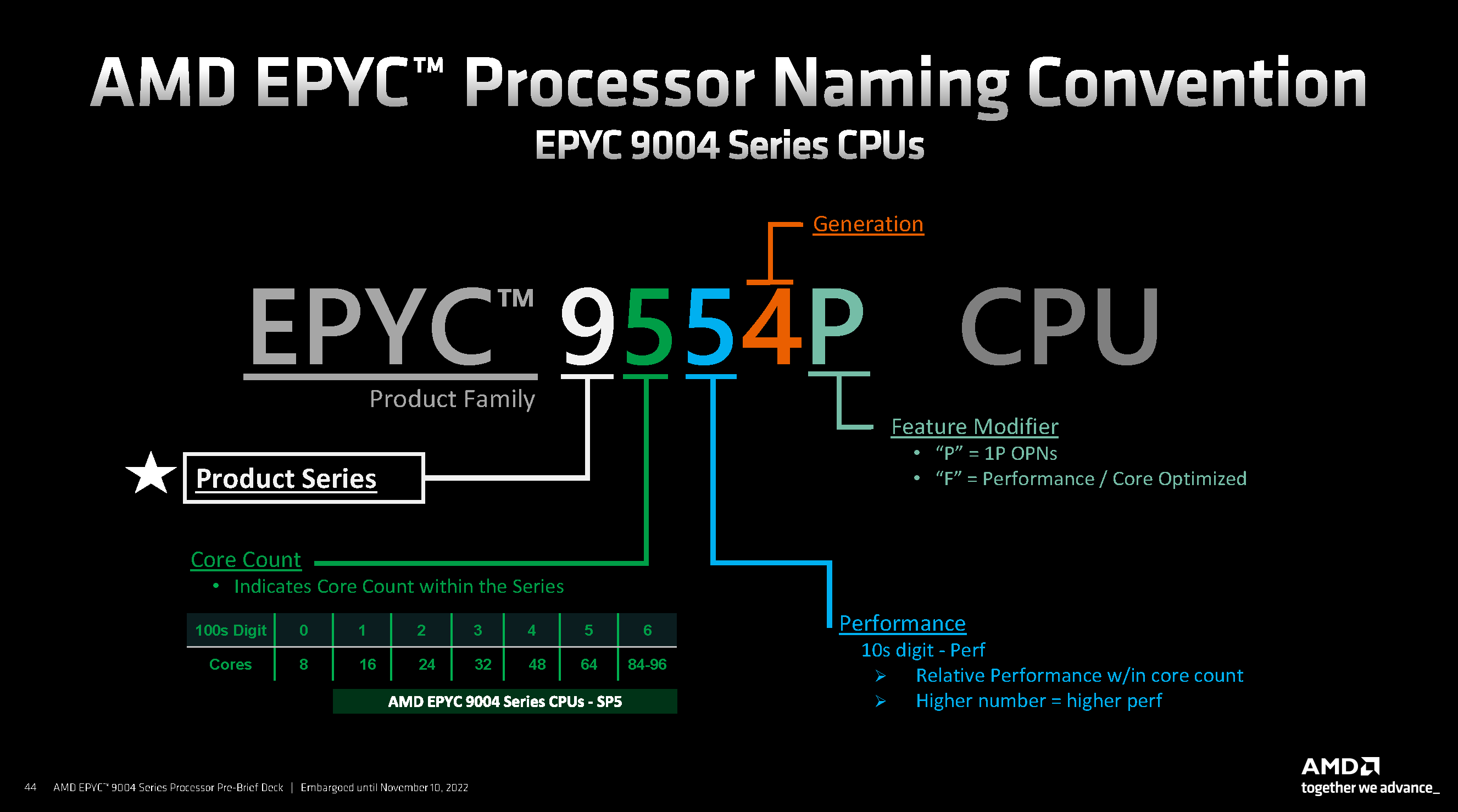
The SKU naming is very straightforward and clear with each number denoting critical information.

AMD keeps the SKU stack simple. Unlike Intel, there aren’t a bunch of SKUs locking out features. There are 3 general categories and 18 SKUs. Core performance (F), Core density, and Balanced/TCO optimized. They do segment based on 1 socket versus 2 socket support. Price per core stay relatively flat aswell.

With Genoa, AMD’s per core performance leadership is usually ~50% on integer workloads and as high as 96% on floating point! Much of the latter is due to memory bandwidth and cache.

The SQL benchmarks are noteworthy as in some database benchmarks, AMD has fallen behind due to their higher core-to-core latency. They still will lag in many of these, but the gap is closing on some of the commonly used ones. The advantage of Sapphire Rapids’ monolithic and 4-die advanced packaging approaches is that those massive relational databases will be much lower latency between cores.

In the HPC performance comparisons, 96C shows it’s still limited by memory bandwidth, but 32C vs. 32C shows that Genoa’s bandwidth advantage is enormous.

Server consolidation is the big story here.

The numbers vary if you use 2P versus 2P or 2P versus 1P servers, but the result is similar. Generally 3 CPUs get consolidated into 1 CPU.

The funny thing about Genoa is that it has so many cores, workloads won’t scale across it, and some applications even break. AMD has gotten large enough finally to be able to access most software ISV and so Genoa launches with most of these teething pains fixed. Back in the Naples and Rome days, this was a pipedream.

To round it out, confidential computing. Confidential computing is about your software not needing to trust who owns the hardware, and being able to keep your data safe. Data at rest and in flight, encryption is an answer that is well understood, but with in-use, the answer is complicated. While Genoa does not fully deliver the vision of confidential compute, but it has brough many innovations in this area which bring it much closer. Confidential compute is a scale after all.
In the subscriber only section, we will briefly give our thoughts on server market share and revenue share exiting 2023, AMD’s stock, and offer a small giveaway.