

AMD MI300 Performance - Faster Than H100, But How Much?
MI400 Broadcom + AMD Anti-Nvidia Alliance Coming With UEC and Open XGMI


Today MI300X is finally released and it’s coming out with a bang. There’s a lot of customers announced, which we discussed volumes and ASP of here, including folks like Oracle, Meta, and Microsoft. We posted the configuration and architecture back in June, so while there are new low level architecture details at the end of this today we will mostly focus on performance, cost, and software. Also big news on the AMD + Broadcom anti-Nvidia alliance.
On raw specs, MI300X dominates H100 with 30% more FP8 FLOPS, 60% more memory bandwidth, and more than 2x the memory capacity. Of course, MI300X sells more against H200, which narrows the gap on memory bandwidth to the single digit range and capacity to less than 40%. MI300X unfortunately was only able to hit 5.3TB/s of memory bandwidth instead of the 5.6TB/s initially targeted.
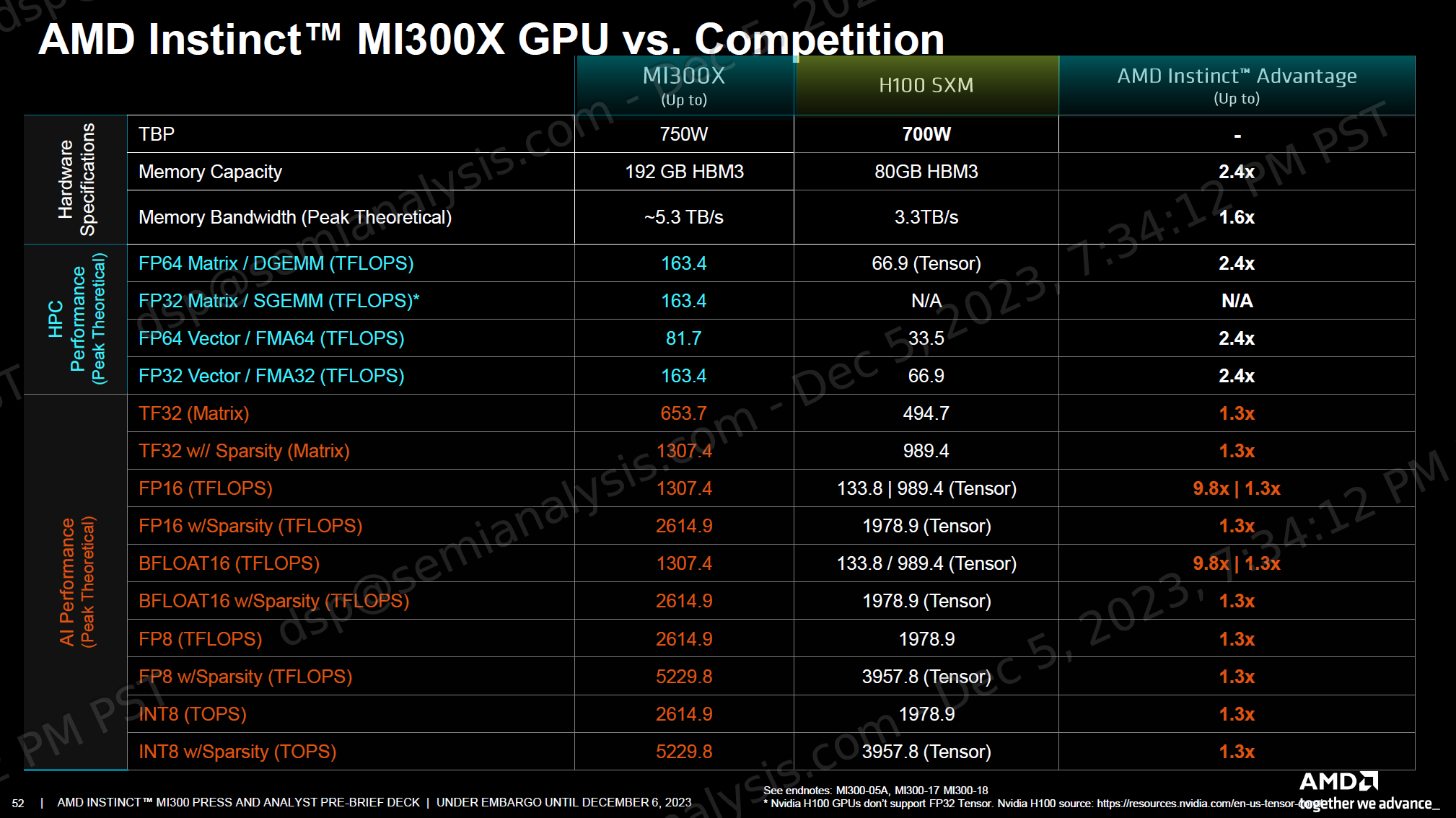
Of course FLOPS, capacity, and bandwidth are only potential capabilities. AMD showed a few different benchmarks, the main theme is they are still quite a bit under on peak performance versus theoretical.
FlashAttention2 - This is forward pass only, IE inference, not training. It’s noteworthy as almost every benchmark AMD shared was forward pass only. The performance advantage is 10% to 20%, far short of the raw specs.
LLAMA2-70B - Again forward pass only for certain kernels, not the full model, and again 10% to 20% performance. These are more compute bound workloads, not memory bound.

Inference on the other hand, AMD showed two different inference benchmarks, one was high batch size and throughput, the other was lowest latency possible.
Bloom - This benchmark is the most impressive of them all, but we think it is one of the classic tricks we have seen other firms do when they have a memory capacity advantage. Use a model that barely fits in the inference system, in this case, Bloom takes a bit over 350GB of memory of the 640GB that the H100 HGX has. Then you use a very large input sequence length (2k in this case) relative to the output token count (100). The system with smaller memory size is forced to run with a much smaller batch size because the KVCache takes up all the memory capacity. Meanwhile AMD can use a larger batch size to leverage their compute. To be clear, this is a real advantage and the throughput focused scenario is real, but it is an edge case.
LLAMA 2-70B - This is a more realistic inference benchmark for most use cases. AMD has a 40% latency advantage which is very reasonable given their 60% bandwidth advantage vs H100. Given H200 comes a lot closer in bandwidth we expect it to perform similarly. Note AMD used VLLM for Nvidia which is the best open stack for throughput, but Nvidia’s closed source TensorRT LLM is just as easy to use and has somewhat better latency on H100.

The last benchmark is LLAMA 2 -13B. The performance improvement is 20% here, not much to caveat here. MI300X is cheaper. H200 likely closes the gap.

On to training. AMD shows a bit of weakness from their software stack here. They only achieves less than 30% of the theoretical FLOPS that MI300 is capabile. Meanwhile Nvidia frequently achieves 40%. As such performance is lacking.
Their performance matches Nvidia because of a few reasons. One of the chief reasons is that AMD only gets about half the theoretical FLOPS in raw GEMM workloads. The other is that FlashAttention2 does not work well on the backward pass still. It is coming, but there are architectural differences that make it tough. AMD’s L1 cache is doubled, but the LDS is still the same size. This is still tougher to make FA2 work versus Nvidia’s larger sharedmem.

Overtime, we expect this to improve meaningfully. That’s the big bright spot to these numbers, we see AMD rapidly improving.

In general, we are watching Triton performance getting better, especially for raw GEMM.
OpenAI is working with AMD in support of an open ecosystem. We plan to support AMD’s GPUs including MI300 in the standard Triton distribution starting with the upcoming 3.0 release.
Philippe Tillet, OpenAI
This is a big deal as OpenAI and Microsoft will be using AMD MI300 heavily for inference.
Also, to be clear eager mode and torch.compile just work for most models in training, fine tuning, and inference for most existing models just work out the box, but what’s lacking is performance optimization. We see it happening.





In a handful of months we’d bet AMD’s performance keeps growing versus the H100. While H200 is a reset, MI300 should still win overall with more software optimization.

The more important thing is OEMs and clouds. Microsoft of course is supporting. Oracle will also be supporting as we noted in the pand they also announced customers such as Databricks (MosaicML).
But they aren’t the only ones.