



AMD MI300 – Taming The Hype – AI Performance, Volume Ramp, Customers, Cost, IO, Networking, Software
Amazing engineering, but what of the path to market?



With massive GPU shortages and Nvidia charging ~5x markups versus manufacturing costs, everyone in the industry is desperate for an alternative. While Google has a structural perf/TCO advantage in AI workloads internally versus other big tech firms due to their mature hardware and software with their TPUs and OCS, there are structural issues that we believe will prevent them from becoming the leader for external use.
Google TPUs will only ever be available from 1 firm in 1 cloud.
Google doesn’t disclose their chips until well after they are deployed where as large buyers need it documented before launch with early access systems available before ramp.
Google has consistently hid multiple major hardware features away from users for years, including memory/compute related and networking/deployment flexibility.
Google refuses to document hardware at a low level externally for those wizards who want to write custom kernels to maximize performance.
The gatekeeping of Google's biggest technological advancements in AI infrastructure will keep them on the backfoot vs Nvidia based cloud offerings, structurally, unless Google changes their modus operandi. Inhouse chips from other clouds such as Amazon and Microsoft are still very very far behind.
In the world of merchant silicon, Cerebras is currently the closest competitor with solid performance on GPT-3 and impressive open-source models, but hardware accessibility is very limited with each individual server costs millions of dollars. The only way to access Cerebras in the cloud is through their own offering. The lack of access hurts development flexibility. The life blood of the Nvidia ecosystem is people developing on a wide variety systems, from their gaming GPU that costs hundreds of dollars to being able to eventually scale to systems with tens of thousands of GPUs on premises or with all 3rd party cloud service providers. While other startups such as Tenstorrent show promise, we believe the hardware/software is still a bit away from really hitting its stride.
Intel, the largest merchant silicon provider in the world, is nowhere to be found despite acquisitions of 2 different datacenter AI hardware firms, Nervana and Habana. Nervana was killed a few years ago, and the same seems to be happening to Habana now. Intel is currently on their 2nd generation Habana Gaudi 2 with little to no adoption besides some instances available on AWS. Furthermore, Intel is already communicating the roadmap as dead with the product being rolled into the 2025 Falcon Shores GPU. Intel's GPU, Ponte Vecchio isn’t faring any better. It is quite late, having only recently completed delivery to the long-delayed Aurora supercomputer, with no successor for another 2 years. It’s performance is generally uncompetitive with Nvidia’s H100 GPU.
As an aside, we will be hosting a discussion about open-source AI, AI hardware, and RISC-V with participation from Raja Koduri, Tenstorrent’s Jim Keller, Cerebras’ Andrew Feldman, and Meta’s Horace He on June 27th in San Jose. Free registration!
AMD MI300 Explaining The Hype
To tame the hype, we must first know why the hype is there in the first place. Everyone wants an alternative. AMD is the only firm that has a track record of successfully delivering silicon for high performance computing. While this mostly applies to their CPU side being a well-oiled execution machine, it also extends further. AMD delivered HPC GPU silicon in 2021 for the world's first ExaFLop supercomputer, Frontier. While the MI250X powering Frontier served its primary job sufficiently, it failed to garner any leverage amongst the big spenders of cloud and hyperscalers.
Now, everyone is looking forward to AMD’s MI300 which will be delivered later this year to El Capitan, their 2nd Exascale supercomputer win. For that reason, AMD’s upcoming MI300 GPU is one of the most discussed chips once you leave Nvidia land. SemiAnalysis has been discussing the MI300 chip’s developments since the first half of last year. We’ve been closely following the software landscape for it with Meta’s PyTorch 2.0 and OpenAI’s Triton. There hasn’t been this much buzz for a datacenter chip since Nvidia’s Volta GPU and AMD’s Rome CPU.

MI300, codename Aqua Vanjaram, is made up of several complex layers of silicon, and is frankly a marvel of engineering. CEO Lisa Su held up an MI300 package earlier this year at CES, giving us a look at how MI300 is structured. We see 4 quadrants of silicon surrounded by 8 stacks of HBM. That is the highest 5.6 GT/s speed bin of HBM3, with eight 16GB or 24GB stacks forming 128GB or 192GB unified memory at a whopping 5.6 TB/s bandwidth.
Compared to the Nvidia H100 SXM 80GB at 3.3 TB/s, that is 72% greater bandwidth with 60% to 140% higher capacity.
AMD's chance to grab any amount of AI computing dollars ultimately boils down to being a reliable 2nd source for hyperscalers vs Nvidia. The assumption is that a rising tide lifts all boats. Surely, massive spending expected on AI datacenter infrastructure will benefit AMD in some way, right?
Well no, AMD hardware is barely a footnote in the AI spending bonanza. In fact, currently AMD is a relative loser in the generative AI infrastructure buildouts due to their lack of success with datacenter GPU, lack of CPU win in HGX H100 systems, and the general shift away from CPU spend. As such, success of MI300 is critical.
This report will take the veil off of AMD’s MI300. We will be covering chiplet design, architecture, IO speed, systems engineering, FLOPS, performance, manufacturing cost, design costs, release timing, volume ramp, software, and customers. While various versions target different markets, we will be focusing especially on the variants targeting AI.
Note this is an extended version of a report + commentary we have been providing to our clients for a few months. First let’s start with the hardware building blocks before moving on to the more business oriented aspects.
The Base Building Block - Elk Range Active Interposer Die
All variants of MI300 start with the same base building block known as the AID, active interposer die. This is a chiplet called Elk Range and is ~370mm2 in size manufactured on TSMC’s N6 process technology. The chip houses 2 HBM memory controllers, 64MB of Memory Attached Last Level (MALL) Infinity Cache, 3 of the latest generation video decode engines, 36 lanes of xGMI/PCIe/CXL, as well as AMD’s network on chip (NOC). In a 4 tile configuration, that is 256MB of MALL Cache vs H100’s 50MB.
The most important part of the AID is that it is modular with regards to CPU and GPU compute. AMD and TSMC use hybrid bonding to connect the AID to other chiplets. This connection, through copper TSVs allows AMD to mix and match the optimal ratio of CPU vs GPU. The four AIDs communicate with one another with a bisectional bandwidth exceeding 4.3 TB/s, enabled with an Ultra Short Reach (USR) physical layer as seen on the chiplet interconnect in AMD's Navi31 gaming GPU, albeit this time with both horizontal and vertical links and with symmetrical read/write bandwidth. The square topology also means that diagonal connections require 2 hops vs 1 hop for adjacent AIDs.

2 or 4 of these AIDs, with varying compute depending on the MI300 variant, are grouped together on top of a CoWoS silicon interposer. There are two different tape outs for the AID, they are mirrored much like Intel’s Sapphire Rapids.
Compute Tiles – Banff XCD and DG300 Durango CCD
The modular compute tiles on top of the AID can be either CPU or GPU.
On the GPU side, the compute chiplet is called an XCD, codenamed Banff. Banff weighs in at around ~115mm2 on the TSMC N5 process technology. It contains 40 total Compute Units although only 38CUs are enabled. The architecture is evolved from AMD’s MI250X, and on GitHub, AMD calls it gfx940, but publicly they call it CDNA3. It is optimized for compute and cannot really do graphics despite being a “GPU”. The same applies to Nvidia’s H100 really, which have most their GPC’s incapable of graphics.
In total, each AID can have 2 Banff dies with 76 total CUs. The max XCD/GPU configuration of MI300 will offer 304 CUs. This compares to AMD’s MI250X with 220CUs.
The other modular compute aspect of MI300 is the CPU side. AMD partially reuses their Zen 4 CCD chiplet albeit with some modifications. They changed a few of the metal layer masks to create bond pads for SoIC to the AID, necessitating a new tapeout with some metal masks redesigned. This modified Zen 4 CCD, GD300 Durango disables the GMI3 PHY. The bandwidth to the AID is significantly higher than GMI3. This CCD is on TSMC’s 5nm process technology and retains the same ~70.4mm2 die size as the Zen 4 CCD found on desktop and server.
Each AID can have 3 Zen 4 chiplets for a total of 24 cores. The max CCD/CPU configuration of MI300 could offer up to 96 cores.
Advanced Packaging - A Taste Of The Future
AMD’s MI300 is the most incredible form of advanced packaging in the world. There’s over 100 pieces of silicon stuck together, all sitting on top of a record breaking 3.5x reticle silicon interposer using TSMC's CoWoS-S technology. This silicon ranges from HBM memory layers to active interposers to compute to blank silicon for structural support. This massive interposer is close to double the size of the one on NVIDIA's H100. The packaging process flow for MI300 is very complex and we will have to dive into it separately another time to talk through the exact process flow and equipment utilized at each step as it really is the future of the industry.


The complex packaging required major flexibility and revisions from AMD to get MI300 on time. The original design was to use an organic redistribution layer (RDL) interposer with TSMC's CoWoS-R technology. In fact, TSMC did present a CoWoS-R test package last year that looks eerily similar to the structure of MI300. Perhaps the change of interposer material was done due to warpage and thermal stability concerns of an organic interposer with such a large size.
AIDs are hybrid bonded to XCD and CCD with SoIC gen 1 at a 9um pitch. AMD had to back off from plans of moving to TSMC’s SoIC gen 2 which has a 6um pitch due to the immaturity. Then those are packaged on top of a CoW passive interposer. Through the process there is more than a dozen pieces of support silicon. A final MI300 contains conventional flip chip mass reflow and TCB as well as chip on wafer, wafer on wafer, and reconstituted wafer on wafer hybrid bonding.
MI300 Configurations
AMD MI300 comes in 4 different configurations, although we aren’t sure if all 4 will actually be released.
MI300A is the one grabbing the headlines with heterogenous CPU+GPU compute, and is the version being used by the El Capitan Exascale supercomputer. MI300A is packaged with an integrated heat spreader on a 72 x 75.4mm substrate, and fits into socket SH5 LGA mainboards, with 4 processors per board. It effectively paid for the development costs. It is already shipping, but really ramps in Q3. The standard server/node will be 4 MI300A’s. There is no need for host CPU as that is built in. This is by far the best HPC chip on the market and will remain so for a while.
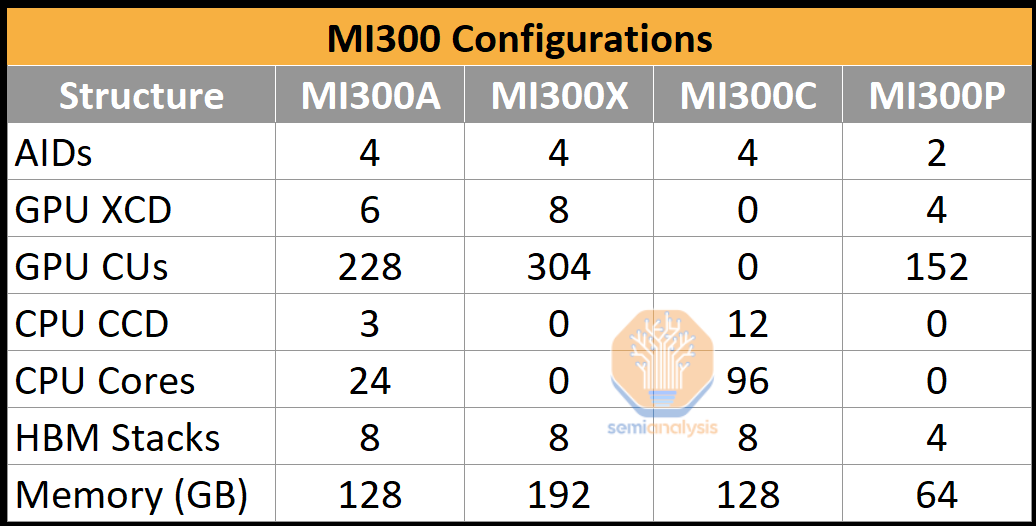
MI300X is the AI hyperscaler variant that if successful would be the real volume mover. It is all GPU, for maximum performance in AI. The server level configuration that AMD is pushing here is 8 MI300X’s + 2 Genoa CPUs. It also comes with higher density SK Hynix 24GB HBM stacks.
MI300C would go the opposite direction and be CPU only with 96-core Zen4 + HBM answer to Intel's Sapphire Rapids HBM. However, the market for this may be too small and the product too expensive for AMD to productize this variant.
MI300P is like a half sized MI300X. It is one that can come in at a lower power in PCIe cards. This again requires host CPUs. This would be the easiest one to get to start developing with, although we think that’s more of a 2024 release.
This report will be covering IO speeds, networking, systems engineering, FLOPS, performance, manufacturing cost, design costs, release timing, volume ramp, software, customer engagements, and competitive dynamics. While various versions target different markets, we will be focusing especially on the variants targeting the largest market, AI.