




AMD has been absolutely crushing it over the last handful of years, ever since the launch of the Zen architecture. They are devouring Intel’s market share like it’s a cheap buffet on a Sunday. Furthermore, this shows no signs of stopping. AMD has built and acquired world class IP that gives AMD high visibility to success over the next few years. The culture of execution at AMD is also one of the most amazing in the industry.
Today we are going to cover the information AMD presented from their Financial Analyst Day including details from strategy to products to roadmaps to technology to finances. We will also present our analysis on top, while in general, this will be positive, there are some areas we believe they are over-stating and over-hyping.
AMD’s strategy can be summed up into one quote from Lisa Su.
No matter who you are, no matter which business you're in, you need more compute.
Dr. Lisa Su, CEO of AMD

AMD started the presentation by going over their current leadership in each of their major areas. Datacenter is the big and obvious one. The initial ramp was slow, with the 1st generation Naples having technology teething pains and very little uptake. The 2nd generation Rome took a very long time to get qualified and brought up at customers, but now, with the 3rd generation of Milan, there is no question that everyone wants to buy as many of these as possible, from HPC to Cloud.
With PC, AMD has made a similar shift and they are moving up the stack. They have really vacated the low end of the market to Intel for the last year and the high end and enterprise is where all their share gains are coming in. Gaming is a bit of a spot where we will disagree with AMDs narrative. Their GPUs are good, but nothing groundbreaking. Most of their outperformance in this area comes from Consoles. In the gaming GPU market, they have undergrown the market, partially due to a less attractive product versus Nvidia and partially due to a severe lack of supply.
The 56% CAGR on revenue has been AMAZING. Part of it is from a covid bump in end markets, but a lot of it is also just pure share gains at the expense of Intel in PC and datacenter.
These share gains are not the only avenue for success. Future growth gets more concrete as you being to look at AMD’s total addressable market and how that has shifted over time.

AMD’s TAM in 2020 was significantly smaller that it is now with Xilinx and growth in some end markets. Looking forward to 2027, the TAM numbers are very interesting and point to what AMD aspires to do to expand out of traditional segments and into new ones with a mix of their own, Xilinx, and Pensando IP. In total, the TAM is $125B. $61B is GPU and AI, $42B is server CPU, $13B is FPGA and adaptive SoC, and $6B is DPU and infrastructure acceleration. Most of these TAM’s are addressable, but some are not.
Now instead of more generalities, we will start diving deeper.
CPU
The bread and butter of AMD’s lead depends on CPU dominance, many of their TAM expansion opportunities rely on AMD being able to provide CPUs and fabrics to others to plug in their custom IP. Intel has the same strategy, so AMD must stay on top here.

First off, AMD has a huge advantage over Intel in terms of area per core, but their comparison is disingenuous. Comparing a single core without L3 cache is flawed because Intel generally has a larger core with larger L2 caches and smaller L3s. AMD optimizes around larger shared L3 caches. Their 8 core chiplet with Zen 3 is ~81mm2 of TSMC N7 silicon. If you count only cores and ignore test circuitry and the die-to-die connection, that is 67.85mm2.
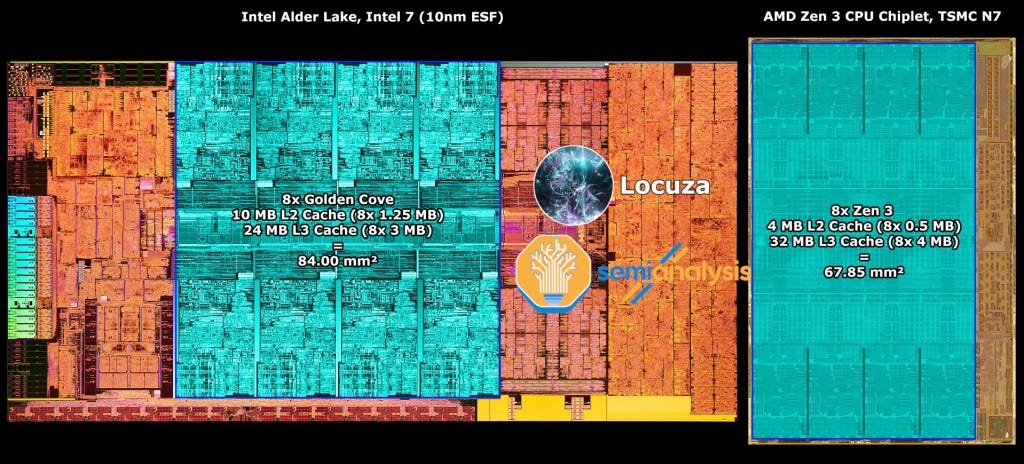
This includes the core-to-core ring bus as well, but not the area for the fabric on their IO die. Intel’s Alder Lake for 8 cores with L3 cache and the general chip’s ring bus stops is ~84mm2, so Intel’s disadvantage isn’t nearly as large as AMD made it out to be. The power advantage is far more important. Furthermore, Intel on there server cores loads up area with a more capable mesh fabric, the data streaming accelerator, more AVX512 capabilities, and the AMX AI accelerator. These give Intel wins in certain workloads, but also make their next generation Sapphire Rapids horrible on cost versus AMD’s Milan and Genoa as we showed off in this article. AMD has much better TCO currently, and this lead will widen with the next generation Genoa vs Sapphire Rapids based on performance claims, estimates, leaks, and our server level cost model. AMD will keep gaining share until 2025 at minimum.
As for the rest of the Zen architecture, it’s nice to see AMD share figures that blow up in the face of all the YouTube and Twitter “leakers.” Zen 5 follows AMD’s 18-month cycle time and should first arrive in the first half of 2024. They say it includes some AI and machine learning optimizations, which is very interesting as Zen 4 already includes VNNI. Could AMD be implementing an AI co-processor like Intel is has AMX?

The TAM breakout is interesting. It’s the first time I’ve seen any of the big 3 (Intel, AMD, Nvidia) break out Cloud vs Enterprise vs HPC. This HPC TAM seems quite a bit larger than we imagined, so I think they likely are including a lot of systems that are not submitted to the Top 500 list.
AMD’s differentiation of architecture across their product stack is very exciting with Genoa being the straightforward successor to the current generation Milan. Bergamo brings about a “Cloud Native” CPU using a modified Zen 4 core called Zen 4C. If you are wondering if this is marketing fluff or a real thing, check out our breakdown of this with regards to Ampere Computing. It included some pure manufacturing cost comparisons as well. Zen 4C doesn’t seem as far along the road to cloud native with larger vector units, SMT, and higher performance, but it is a low overhead variant that makes their main core much more competitive.
Lastly, AMD teased Siena which you should think of as half of Genoa. It will have some different capabilities but by and large, it will be half of Genoa in every way. Power should be down a little more than half though because of the way things scale for the on-chip fabric.
Fabrics
AMD’s fabrics are very exciting and the most critical part of the company in our eyes. There’s a reason for the title. Thinking through the custom silicon business, this is the critical piece of technology that wins or loses them deals. Alongside their packaging capabilities, it is also how they integrate all their existing IP quickly and efficiently to make the best product for each market without huge design expenses.
AMD can make the best CPU or GPU or FPGA in the world, but customers will ditch them if they cannot bring something differentiated to the table. Products are going to get more and more tailored to their specific applications. Volumes fall and design costs rise unless chiplets and amazing fabrics are developed. AMD has both of these.
Customers have come and asked us, hey, can you help us differentiate?
We don't want to build all the general-purpose stuff that you guys are doing because you have the scale in the general-purpose stuff, but we want to be able to add our secret sauce.
We already have the leading industry platform for chiplets, but what we're doing is we're going to make it much easier to add third-party IP as well as customer IP to that chiplet platform.
Dr. Lisa Su, CEO of AMD
AMD’s defining moment with their fabric comes with Infinity Fabric 4. Infinity Fabric has generally sat on top of the same PHYs that are designed for the PCIe standard but utilizing a different protocol. Things get tricky with CXL and UCIe in the play. CXL is a big deal for coherency between accelerators and hosts, pooled memory, and in general, disaggregated server architecture. AMD wants to leverage this while also providing enhanced capabilities.
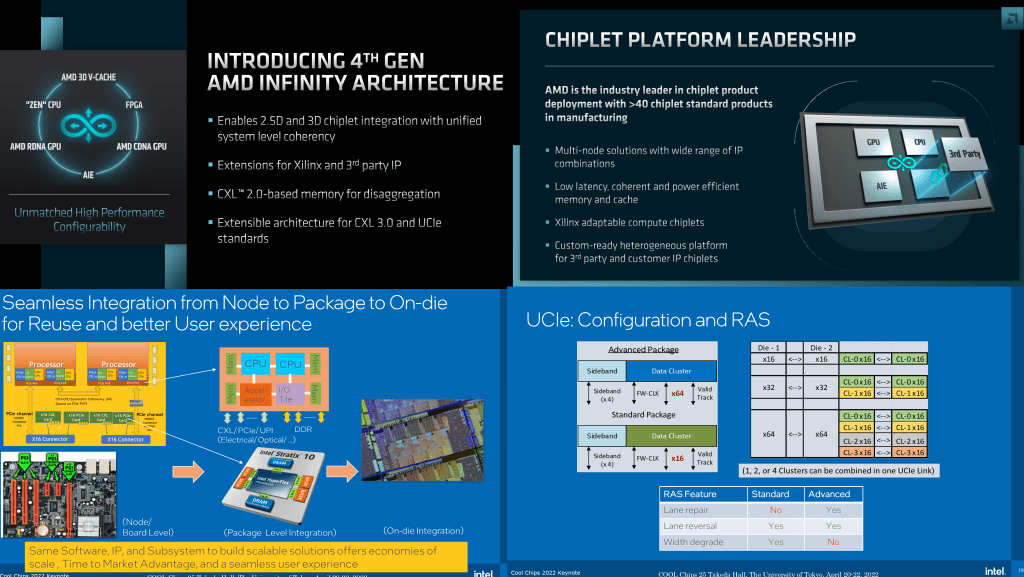
AMD seems to be saying their infinity architecture can leverage the PCIe or UCIe physical layer while also being compatible with PCIe, CXL, or their own protocol layer. Basically AMD seems to be able to jack of all trades it. If you want to make a separate PCIe accelerator, they will support it. If you want to make a UCIe compliant chiplet with 64 lanes of CXL, they will support it, and if you want to make the same width but lower latency AMD proprietary protocol, they will support that too. Then they can have layers of backwards compatibility to where they can drop down to CXL or PCIe if the endpoint doesn’t support Infinity Fabric.
They will be adding this support to Xilinx chiplets, GPU chiplets, and 3rd party’s who want to design chiplets for the UCIe or Infinity ecosystem. It’s a pretty stellar move, and we believe if AMD can execute on this, they will get a decent piece of the pie. Intel also will be supporting UCIe attached chiplets for 3rd parties and they are pushing this hard. This gives 3rd parties a way to leverage multiple packaging and server ecosystems with the same chiplet that works in a coherent manner with Intel or AMD.
AMD’s infinity fabric also should then support co-packaged optics. As we discussed in the past, and have since gotten confirmed, Nvidia and HPE will be using Ayar Labs co-packaged optical tiles over UCIe, and AMD can slot into that same ecosystem due to the standard of UCIe being shared. AMD can then interoperate with their own first party packages using Infinity Fabric protocol, or even an Intel, HPC, or Nvidia packages using CXL.

The real kicker is of course what this means for hyperscalers, automotive companies, telecommunication providers, and consumer hardware companies. AMD hyperscalers can mix and match AMD CPU, AMD GPU, Xilinx FPGA, Xilinx AI Engine, in-house customer chiplets, and 3rd party chiplets to architect the best possible product to maximize power, performance, and TCO.
Datacenter GPU And AI
This is the segment we are least positive on. AMD includes a whopping $61B in their TAM figures here. Currently there is no way AMD can address the AI training market. The Xilinx products aren’t that competitive in most inference workloads either, despite AMD and Xilinx slides telling you they are. AMD GPUs currently exist only to serve government HPCs.
Even in this purpose they aren’t quite up to snuff for general purpose workloads. They work great for highly tuned software, but that is not most workloads. AMD has amazing hardware, but the software is not there. We are hopeful for the promises AMD makes about ROCm 5 just because Nvidia needs a competitor, but even in the Q&A, some of their tone regarding ROCm support on the GPU lineup didn’t inspire confidence.
With that said, AMD has 5,000 software engineers and are hiring aggressively, so hopefully in a few years’ time they will be a lot better. ROCm 5 is supposed to finally enable RDNA gaming GPUs which is huge. MI200 is ballpark $10k+ and not everyone is willing to throw down that much money for a GPU, or pay for cloud fees in developing. RDNA gaming GPUs come for $250 and on, so that should assist heavily with development by startups, students, and in general getting people comfortable with developing on their software stack.

AMD is finally offering an SDK for developing and deploying pre-optimized AI models. The big question is with what level of optimization they will provide and what breadth/depth of models. The optimistic view is that many in the industry are desperate for someone who will challenge Nvidia, so they are providing a lot of support. This includes governments, research institutions, and hyperscalers. The majority of companies and people will just go with the easy option, which is just Nvidia. Catching up will take many years
Despite the awesome specs of AMD’s current generation GPU, the actual performance in datacenter GPU workloads tends to not be as impressive. This is despite AMD using nearly twice as much silicon (2 large N7 dies vs Nvidia’s A100 and her 1 large N7 die) and 8 stacks of HBM active vs Nvidia’s 5 stacks of HBM active. All this means AMD pays a lot more for manufacturing relatively. Their use of ASE’s FOEB packaging is not going to change that cost curve meaningfully either.
AMD’s strong point here is their hardware engineering. AMD’s next generation MI300 is a marvel of engineering. AMD’s claims for performance per watt are stellar. While Intel and Nvidia have visions of combining GPUs and CPUs into the same package, AMD is going to start installing them into next generation HPCs in H2 of 2023. Furthermore, AMD is doing it all in 1 package with truly unified HBM memory. We have written exclusively about the packaging of MI300 in the past, but it is going to be amazing, far ahead of what Intel and Nvidia will deliver in the same time frames.

The performance claims seem stellar, especially when you look at some of AMD’s footnotes. 8x AI perf, with 5x perf/W in AI for example is simply nuts! AMD measured MI250X at 306.4 TFLOPS of FP16 performance at 560W TDP. That is 80% of its theoretical peak performance. AMD’s claim for MI300 performance uses FP8, so a bit disingenuous of a comparison give differing number formats. Regardless, using AMD’s claims puts MI300 at roughly 2400 TFLOPS of FP8 at 900W TDP to achieve both 5x perf/W and 8x perf vs MI250X. Nvidia’s Hopper GPU alone is 2000 TFLOPS of FP8 at 700W, but it is missing the CPU component. Once the Grace CPU component is included, power would rise to about 900W, but it would also get a mild performance increase from the CPU cores. Raw TFLOPS/W are similar.
Nvidia’s Grace Hopper is shipping in volume in H1 2023. It is also a design that can scale to much higher volumes due to the differences in packaging and cost to manufacture. The major drawback is that it still must transfer data out of the package to go between the CPU and GPU. While this is going to be a relatively high bandwidth, low latency link, nothing can compare to on package transfers. The specs of Grace are pretty well known. On the MI300 front, outside of a public GitHub repository we looked through which we do not want to reveal, there are no public hardware specs.
MI300 seems unquestionably higher performance per package, but system scaling is more important for large-scale high-performance computing such as AI. Nvidia can scale NVLink across many nodes, AMD cannot scale Infinity Fabric in the same way. Furthermore, AMD will have a much smaller memory pool versus Nvidia. For commercial deployments, we expect AMD to cost more but perform much better on a single chip or single server basis. Once applications scale up to dozens or hundreds of servers, Nvidia likely has the advantage. That is assuming AMD gets their software together. Programming model, performance in real world applications, and power consumption in those applications will decide who wins.
DPUs, Infrastructure Processing
We have written a lot about DPUs and IPUs on this newsletter, but AMD looks to have competitive offerings here. Clouds use a lot of compute power on infrastructure services such as networking, security, and storage services. DPUs aim to solve this problem by offloading them onto the networking card themselves which pair CPU cores and fixed function offload capabilities alongside more standard networking IO. Amazon is the furthest along this path with their Nitro DPUs, but Nvidia, Marvell, Intel, and AMD are all in the race as well.
Currently AMD does well with their Xilinx FPGAs. This is due to being far more programable and flexible. For example, the FPGA based NICs are the defacto standard for high frequency trading. Microsoft also uses FPGAs heavily in their Project Catapult network infrastructure, but they don't seem to be Xillinx ones. These technologies are also great for 5G and edge, but this will fall to the wayside as we move forward, FPGAs will not dominate this area forever, and ASICs will come to play.

That is where the Pensando acquisition comes in. The most difficult part is software, and FPGAs are horrible for this aspect. We have heard from actual users of the hardware that Pensando has some of the best software for this market. They use open standards for the networking flow such as P4. The acquisition was a no brainer as Pensando needed AMDs backing as Intel, Nvidia, and Marvell are investing very heavily into hardware and software for this field, and AMD needs this IP for datacenter and edge. We expect Intel to be the highest volume DPU provider in 2023 due to their Mount Evans ASIC, but the DPU market is very early days and the landscape is constantly shifting.
x86 is certainly where a lot of our compute solutions are, but we all recognize that ARM has a lot of traction, frankly, in our Xilinx roadmap and our Pensando road map will use ARM. We would also use in this environment for custom -- really the technology of choice of the customers.
Dr. Lisa Su, CEO of AMD
Also, a fun sidenote, Locuza figured out that the die shot AMD presented as 7nm Elba, but is actually of the 16nm Capri chip. Tsk tsk to the marketing person who made these slides!
FPGAs, Adaptive Computing, And The AI Engine
We are generally not the biggest bull of FPGAs. The pure FPGA business including Xilinx FPGAs, Lattice FPGAs, and Intel FPGAs, should undergrow the general semiconductor market. AMD talked up a lot of these end markets, but as the markets mature and reach a critical mass, more hardened solutions will be created and take up and incremental growth in that market. It’s happened many times in the past, and with the future of open chiplet ecosystems, it will only accelerate. With that said, the IP Xilinx has is critical to winning other much larger TAMs.
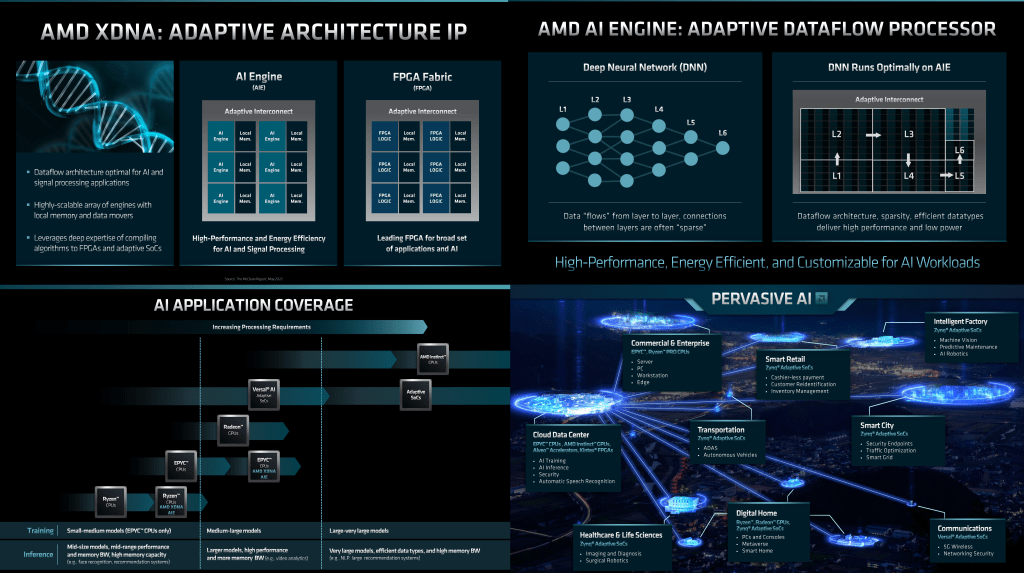
The AI engine that Xilinx has developed will slot into many markets nicely. AMD has multiple products in the works that include this AI engine. This work started as a licensing deal well before AMD even acquired Xilinx, so products will be coming relatively quickly, with AMD’s consumer laptop SOCs getting it next year and the datacenter CPUs getting it in 2024.
The AIE also opens up many other markets. Telecom markets can get it with AMDs telecom CPU roadmap and semi-custom efforts there. This AI engine would be useful for FEC, beam forming, and many other use cases. Likewise, it would be useful in datacenter and telecom networking markets as well for security and threat detection. It could also be used for semi-custom automotive efforts for a variety of self-driving applications. This IP is the perfect fit for AMD as they lack AI chops, and it can go into all of the emerging buzzword soup environments that will make AI a humongous industry in the future.
The AI engine should be highly scalable, fast, and common across many different product categories. It is a spatial data flow architecture, which is distinctly different from how many AI accelerators currently operate, including GPUs. In short, it is a tiled architecture with local memory and local x and y data movement. It can scale up, but it would have a hard time with ingesting tons of data for training. It should be much better at inference, which is what’s more relevant to all the end markets that AIE will be going into.
The software aspect is the most interesting and important part. If AMD can nail this, then they will hit a homerun.
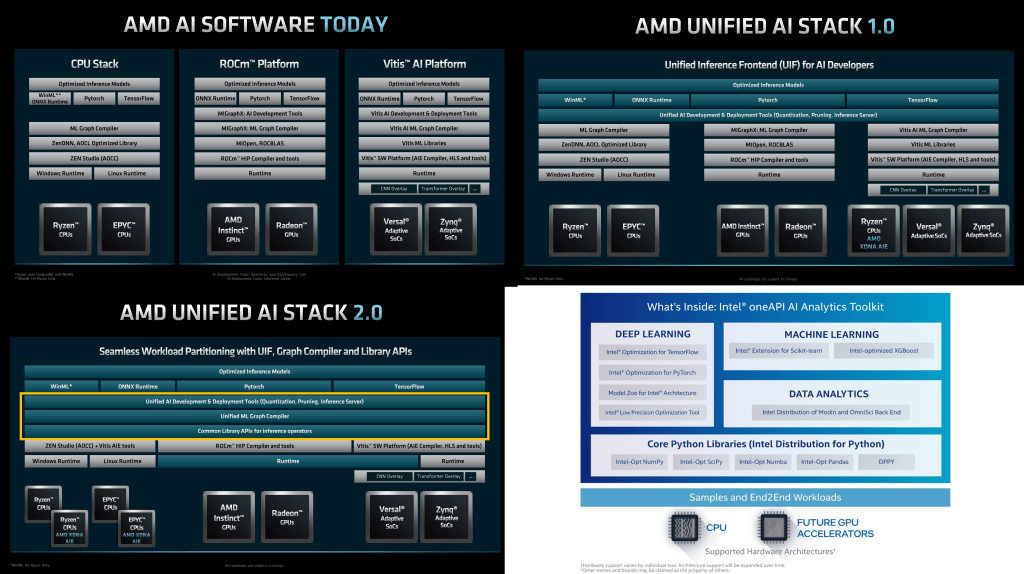
AMD has separate software platforms for their CPU, GPU, and Xilinx AI engines. They announced they will be unifying them under the Unified Inference Frontend for AI developers. This is somewhat similar to what Intel is doing with OneAPI (slide shown), but really it is more similar to Intel’s OpenVINO. While OneAPI has very little traction, their OpenVINO has been a massive success. AMD has a long road ahead of them to equalize here, but it is a solid plan.
The first generation will unify pruning, quantization, and inference deployment. In essence, a common framework for optimizing models. The second generation will unify the graph compilers and bring a common library for inference operations. There will still be a lot more work here to catch up to Intel’s OpenVINO, especially with regards to the huge fragmentation lower in the stack, but it is a solid start.
The only other interesting thing revealed from a pure FPGA perspective is that Xilinx will be skipping 5nm entirely. This seems odd given all the well-publicized issues with TSMC’s 3nm and how amazingly their 5nm technology has been ramping and performing. Graphcore is also doing the same with skipping 5nm.
Client
The new PC TAM of $50B is a load of crap in our eyes. This would require the PC market to be in the ~450-million-unit range, which is very hard to imagine after the last decade. The total TAM is not expanding in PC as fast as AMD or Intel are expecting. We don’t have too much to say here besides that AMD will steadily gain share, but not anywhere close to the same pace they will in datacenter. Those gains will almost exclusively be in the high-end of the laptop market.
AMD is not going to be competitive on price with Intel on the low end, nor do they want to be. Phoenix and Strix should beat Intel on the efficiency and GPU side of things, which will keep them accelerating in the high end. AMD is rightly focusing on where their IP advantage can be leveraged, premium laptops. The low end of the laptop market and most of the desktop market is where Intel can keep flexing their IDM muscles.
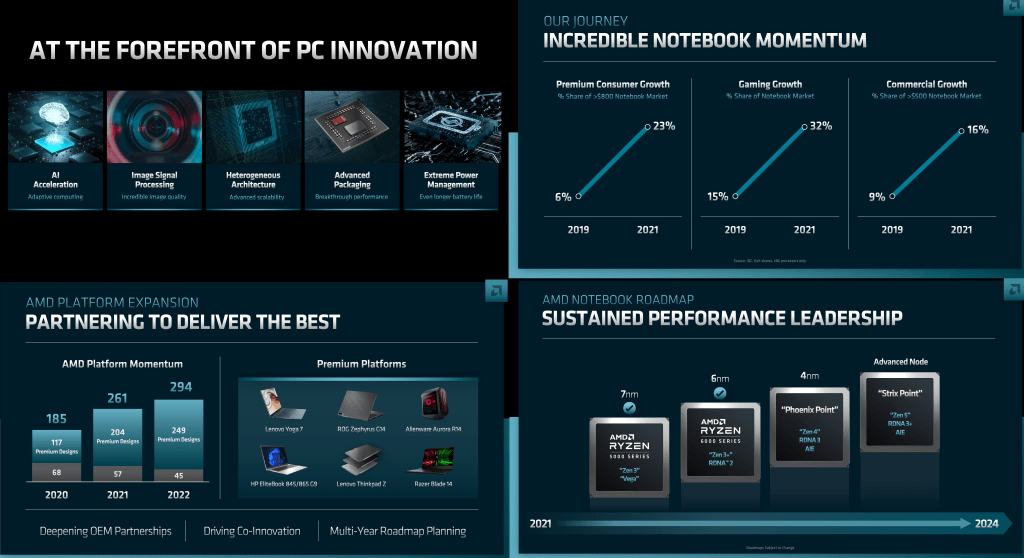
Gaming is nice, but it will be important to see if AMD can break the mindshare and features that Nvidia can bring to the table. AMD doesn’t have the performance lead this generation and they won’t next generation either. That mindshare doesn’t break until they have the totem position for multiple generations. With that said, the hardware disparity between AMD and Nvidia is rapidly dissipating, but that’s why Nvidia’s software features and mind share keep them way out in front.
Financials And Should You Buy?
This is where the finance hat goes on. We will be discussing why we would or would not buy this stock over the short term and long term as well as some more around the competitive landscape for the stock. That will happen in the subscriber only section.