




Apple announced their new 20 billion transistor M2 SoC at WWDC. Unfortunately, it’s quite a minor uplift in performance in some areas such as CPU. Apple’s gains mostly came from the GPU and video editing side of things. The overall performance gains are quite disappointing when you factor in the raw cost increase that comes with this new M2 and the fact that it has been nearly 2 years since the M1’s introduction. The cost increase story is similar to that which we wrote about on the A16 where Apple is being forced to diverge SoC choices to A16 on Pro iPhone models and A15 on normal iPhone models due to bill of materials concerns.
Today, we will be discussing details related to the architecture of M2 and Apple’s future designs including M2 Pro/Max and M3 that weren’t discussed at WWDC. We will also do a die area analysis of the images of M2 that Apple released with the help of Locuza. If you prefer to listen to this rather than read, we have created a YouTube video.

It’s very odd that we have seen some pundits talk about this being M1.5 or M1+. That is just nonsense. M1 was generally based on the same IP blocks as the Apple A14 outside of a few deviations. M2, codenamed Staten, is generally based on the same IP blocks as A15, codenamed Ellis. The codenames being based on some of New York’s most well-known islands which should be a hint to how closely related these architectures are. A lot of the disappointment in performance uplift comes from weak gen-on-gen gains given the nearly 2 yearlong gap versus M1. Many people expected more out of the M2.
We discussed this in the past, but a lot of the slow down stems from Apple losing leagues of amazing engineers to firms such as Nuvia and Rivos. The bleeding hasn’t stopped in recent years as Apple’s work culture simply isn’t the best and other firms, namely the hyperscalers such as Google, Microsoft, Amazon, and Meta, are paying more than Apple was to poach talent. Lastly, there has also been an exodus of non-money motivated engineers who think they were successful in transitioning Apple off of Intel silicon, and onto the in-house silicon. These engineers have also left to work on what they believe are more interesting projects elsewhere in the industry whether it is the hyperscalers or traditional firms.
These departures have culminated in A15 and M2 as well as potentially the upcoming A16 to deliver more tepid CPU gains. We have heard that the A16 will not utilize the next generation Armv9 based core which is quite sad if true given Apple was the first to implement Armv8. We have heard this next generation Armv9 core will only come in M3 which will be Apple’s first product on the TSMC’s N3 node. Apple has already designed and taped out the M2 Pro and M2 Max which are still on N5 and A15 base IP.
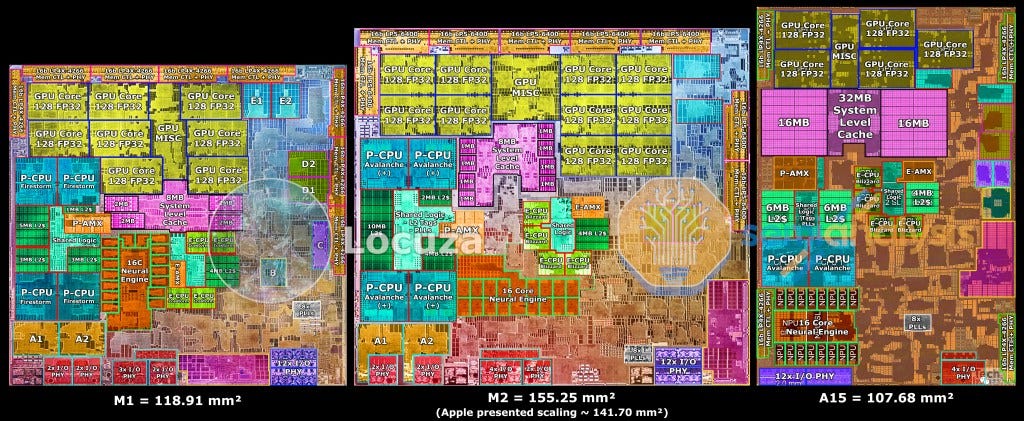
Let’s dive into the die shot. Apple presented an un-marked image of both M1 and M2. This showcased that M2 was 141.7mm2 but we believe Apple modified the die image. This wouldn’t be the first time. Apple did the same with the M1 Max where they hid the die-to-die connection used in the M1 Ultra. They also shifted the size dimensions.

Apple’s image seems to be off scale with M2 as well. One could make out SRAM cells and PHYs which should be identical across the chips and see that M2 seems smaller than it should be. Apple’s presented M2 also appears to have higher transistor densities than the A15 which also is out of whack. It would have lower density due to the smaller total area dedicated to high density SRAM cells and higher total area dedicated to IO and other logic. For that reason, Locuza scaled the M2 die. This scaling brought SRAM cells and identical PHYs equivalent to what Apple has on the M1 and A15. The funkiness of Apple’s marketing image does mean there is an error window of about 3% after the die was scaled in size. The numbers are presented as measured despite the error bars.
Let’s move onto how Apple spent the increase in die size.

First let’s start with Apple’s P-Core. It is based on Apple’s Avalanche core which showed up in A15, although there are some minor differences. This follows how M1 Pro and M1 Max also had a modified Firestorm that could handle larger memory sizes by implementing a larger PA. The M based cores also have a few modifications which help with varied page sizes that must be supported in MacOS.

The core itself is 21% larger than in M1, and 7% larger than A15. The big area of gen-on-gen growth is with the shared L2 cache which has gone from 12MB to 16MB compared to both M1 and A15. The AMX unit looks identical across A15 and M1 as well. The shared logic plane is also significantly larger which is is an indication that there is more bandwidth between the cores and the L2 cache and SLC. Overall, Apple spent 5.2mm2 on the big P-Cores, but the performance increase from them comes mostly from clock speeds. The IPC increase is quite small as documented in reviews.
One very interesting change is that the ROB appears smaller in the Avalanche core that is found in A15 and M2 versus the Firestorm core found in M1 and A14. This is especially interesting because Apple has the largest ROB in the industry in order to achieve the widest and highest IPC core in the industry.

The E-Core was the main unit of change from a CPU perspective from the A14 to A15 and that holds true here. After scaling the Apple provided die shot, the E-Cores look nearly identical between the A15 and M2 which is a good sign that the scaling was accurate. Apple does less or no modification for the E-Cores for Mac silicon where as they do some tweaking and different physical design for those changes on the P-Cores.

There isn’t much to say here about the E-Core as it is pretty clearly the same as the A15 which has been extensively tested. The E-Core complex as a whole is only 1mm2 larger gen on gen while the entire CPU complex is 6.2mm2 larger.

The GPU after scaling also appears to be nearly the same size per core versus the M1 at 128 ALU. This is very interesting because it is one of the areas that M1 diverged from the A14. There was an architecture change there even though they are in the same generation. Apple has precedent for the X SoC to have changes versus the A SoC. A6 and A6X had different GPU architectures many years ago for example. Given the M series SoC's are just a rebrand of the X series, this tracked. This generation the GPU core itself seems unchanged, but the shared logic and miscellaneous is larger so there could be changes on some fixed function aspects. The core count is the major change where Apple bumped it up to a 10 core GPU. We can exclusively detail the GPU clock speed, which went up from 1.27 GHz to 1.406 GHz

In total the new GPU adds nearly 7mm2 gen on gen. This is a worthwhile performance increase, although Apple indicated that power consumption was up slightly at the maximum performance level. At the same power level, Apple still gets nice performance increases though due to better memory and an overall wider/slower design. We also included the NPU and SLC figures here. The NPU figures come across as a little odd, so we will skip over those. The SLC is where things are interesting.

Each 2MB Data Array is generally the same size across M1, A15, and the scaled M2 die which makes sense and justifies our scaling based on identical PHY size. There is no SRAM shrink from the 1st generation to 2nd generation N5 process node. Despite this, the SLC does grow somewhat in size on M2, likely to have more BW to the various IP blocks such as the larger GPU.

The last IP block to compare is the memory controller + PHY. Apple increased the area here significantly to support LPDDR5 6400. The image above is for 1 unit, but the memory controller is multiple channels of course. The total area dedicated to the 128-bit LP5 bus is about 14mm2 versus 8.1mm2 on M1 with its 128-bit LP4X and 4.3mm2 on A15 with its 64-bit LP4X. The real kicker on a cost perspective is fact that LPDDR5 6400 is significantly more expensive than LPDDR4X 4266.
This is also a big part of the equation for Apple doing a split A15 A16 lineup on this year’s upcoming iPhones. We wrote about that decision here. Overall, Apple has to contend with similar issues on the M2 which is why they are keeping M1 based models around for the low end. The combo of minor wafer price increases, larger dies from 118.91mm2 to 155.25mm2, and more expensive memory hurts a lot.
The last IP block which we did not explicitly measure is the much larger media engine to enable the enhanced media capabilities. Apple’s M series is by far the best silicon for creative professionals. There is no question here. If you work on the Adobe suite, M series silicon is the best.
If you liked this work, consider subscribing to the free or paid newsletter. Also please head over to Locuza’s Twitter, Patreon, and YouTube to support his work.