



GPT Model Training Competition Heats Up - Nvidia Has A Legitimate Challenger
Cerebras Is Now Cost Competitive For Training GPT-like Large Language Models

Unless you’ve been living under a rock, large language transformer models are clearly going to change the world. Don’t believe us? Check out OpenAI’s Chat GPT. The capabilities are nuts, from coding to quantum computing to search to art to creative writing to hacking to healthcare.
If you’ve followed our newsletter for a while, you know that we aren’t the best at grammar, but over the last few months, that’s changed. We even use semicolons in sentences! No, we didn’t hire an editor; we use a GPT-like model to grammar check and suggest rephrasing. Some firms have even disclosed that language models’ code generation capacities now contribute to as much as 25% of new additions to their codebases.
The tough pill to swallow with these large language models is the training cost. With large models such as OpenAI GPT3, Google Pathways, DeepMind Chinchilla, Nvidia Megatron, etc, a massive company with deep pockets funding the enormous compute bill. Since GPT3’s release, the conversation has revolved around a few metrics.
How much does it cost to train?
Is there anyone who can break the moat of Nvidia because their GPUs are so expensive?
For the answer to the first question, stay tuned because here at NeurIPS, we have seen and heard some crazy rumors about OpenAI’s GPT4 and future DeepMind models.
For the 2nd and 3rd questions, some firms are starting to break the moat. While most of the industry is using GPUs, both Google and their sister company DeepMind are using the in-house TPU for training large language models. Furthermore, Google TPU has a few external customers, namely Cohere. Cohere is building large language models which can be accessed via an API.
Cerebras, the company making chips the size of entire wafers, released some very compelling benchmarks for GPT-style models running on their Andromeda system. Andromeda is a 16 CS-2 wafer-scale system with a combined 13.5 million AI cores fed by 284 64-core AMD EPYC Milan processors. These systems are linked together with their SwarmX fabric link, which provides more than 96.8 terabits of bandwidth.
This is the first time any vendor has ever released information that can be directly compared to Nvidia in the AI training battleground that matters, massive models. It’s very telling that Intel, AMD, Graphcore, SambaNova, etc, have training dedicated chips, but can’t show off their supposedly special hardware in large-scale clusters with large models.
We compared Cerebras’s results to those from Mosaic ML. Mosaic ML is a machine learning training orchestration platform. They are cloud and hardware agnostic, utilizing multiple public clouds, and their own internal datacenters to minimize training costs. Mosaic is a good basis for an optimized GPU stack that is also easy to use because the user doesn’t have to deal with many of the typical hardware-related and scaling issues.
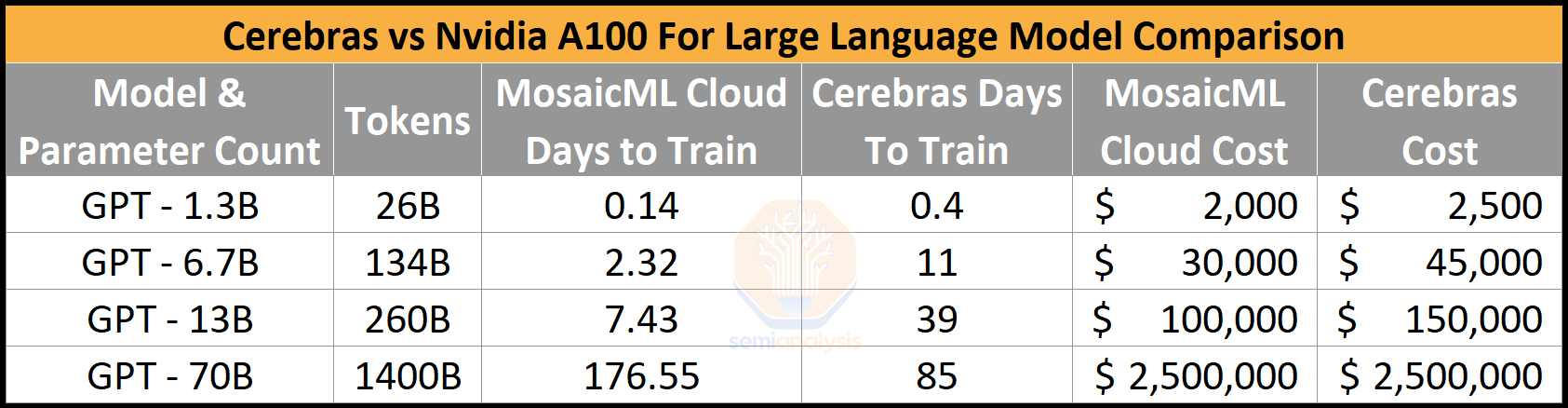
Cerebras and Nvidia are cost equivalent for training a large GPT style model!
Cerebras is behind Nvidia A100 GPUs on smaller GPT models, but they catch up as the model sizes increase.
Cerebras claims they will get a lot more efficient, especially with the addition of techniques like unstructured sparsity.
Mosaic ML also says they can do better now with some clever techniques that they have implemented on the backend. Mosaic’s current goal is to bring the cost to train a GPT 3 quality model from $450k to $100k. As Hopper begins to become available next year, it is likely that it brings significant cost improvements.
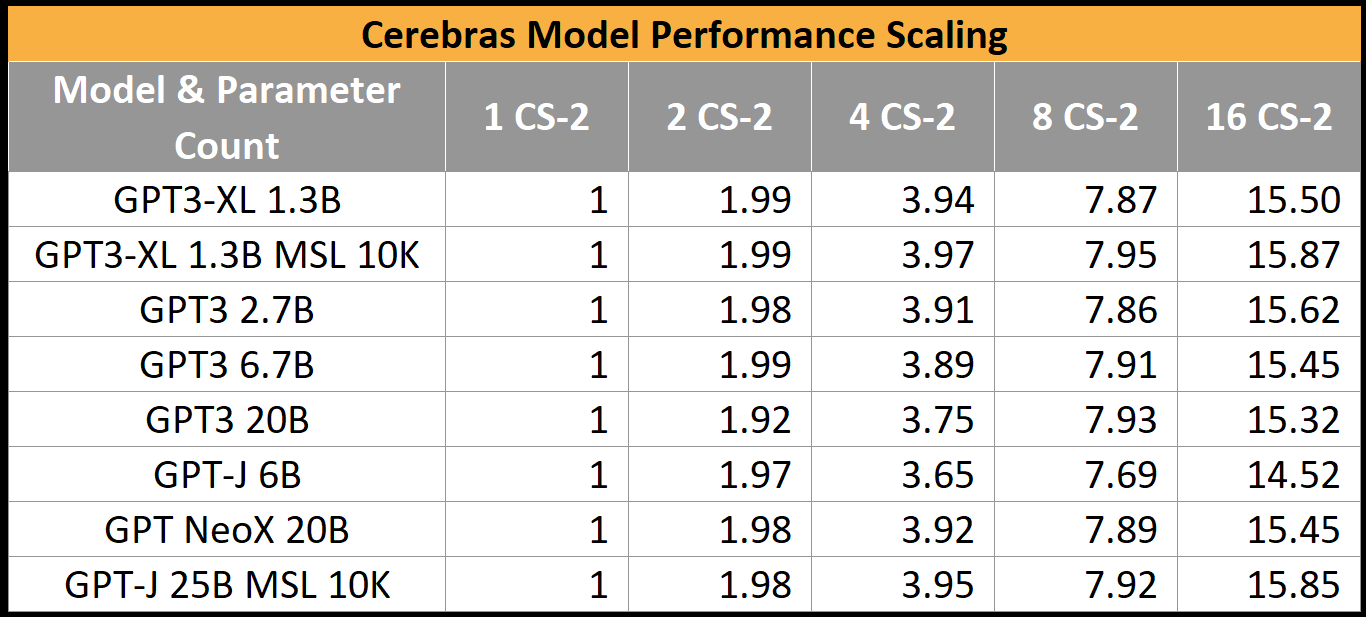
The other thing you may have noticed in the table is the days to train. While we did include this, we wouldn’t look too closely at it. Training time is a function of how large of a cluster of chips you can obtain. Scaling with GPUs and Cerebras Wafer Scale chips seems to be near perfect, ignoring the batch size issues. The first handful of results from Cerebras only uses 4 CS-2, with the largest using all 16 CS-2.
Cerebras also mentioned that long sequence lengths are "GPU impossible". That's simply not true. Multiple LLM companies and tech giants can do long sequence lengths with standard GPUs just fine, with very little effort.
Cerebras has signed deal with the $1.7B AI startup Jasper to provide compute, which is big news!