




Recently MLPerf v1.0, an industry standard on measuring AI performance in standard models, was released. MLPerf Training measures the time it takes to train machine learning models to a standard quality target in a variety of tasks including image classification, object detection, NLP, recommendation, and reinforcement learning. Processors from the likes of Nvidia, Google, Graphcore, AMD, Intel, Habana, and Huawei all made appearances from a variety of server OEMs.
Nvidia offered the widest array of results from 4 GPUs all the way through 4096. Google also had some extraordinarily strong showings as well in the few benchmarks they did submit. One of the negatives of MLPerf is that many firms will only submit results in the few models where they excel, and they will simply leave the rest empty.
Graphcore came out with some interesting results for the closed division. They tested 4 different system configurations, 2 different software stacks, only to submit… 4 total results. Yes, you heard that right, they submitted 1 result per system. This is quite bizarre. No other hardware vendor submitted only 1 result for each independent system. Even Huawei and Intel/Habana submitted multiple results for a system.
Furthermore, they cherry picked submissions further by only submitting results to 2 different models. For the image classification network, ResNet-50, they used a TensorFlow SDK. For the natural language processing network, BERT, they used PopART. This lines up with what we have heard through the grapevine about Graphcore hardware. It has a poor software stack and requires a load of hand tuning by very skilled programmers.
Even with the selective cherry-picking of benchmarks that were clearly very hand tuned, GraphCore tried to call this a win. These results by the way were really bad even when looking at their marketing.
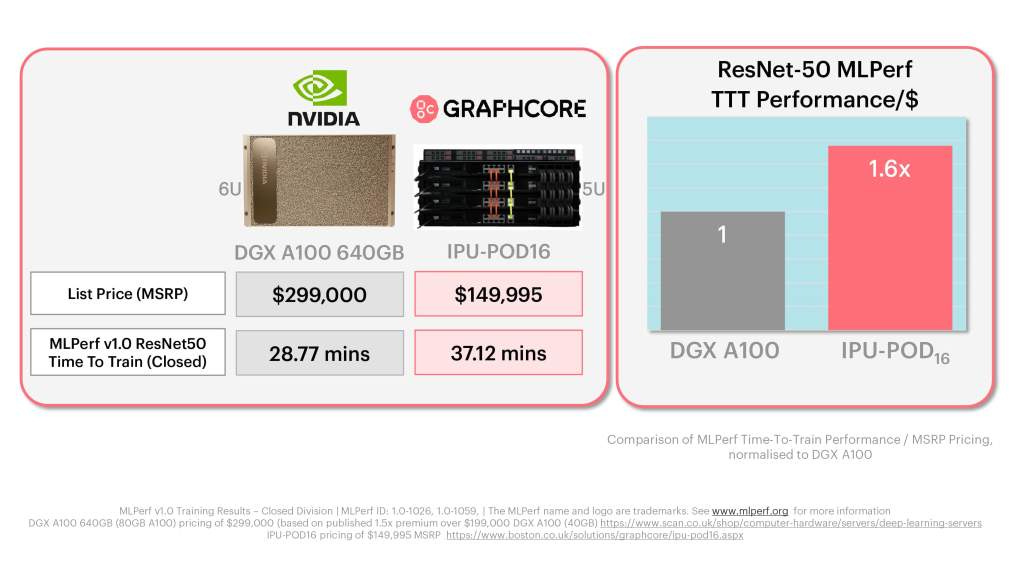
And they get worse as you scale up from the tiny ResNet50 to the slighty larger, but still small BERT model.
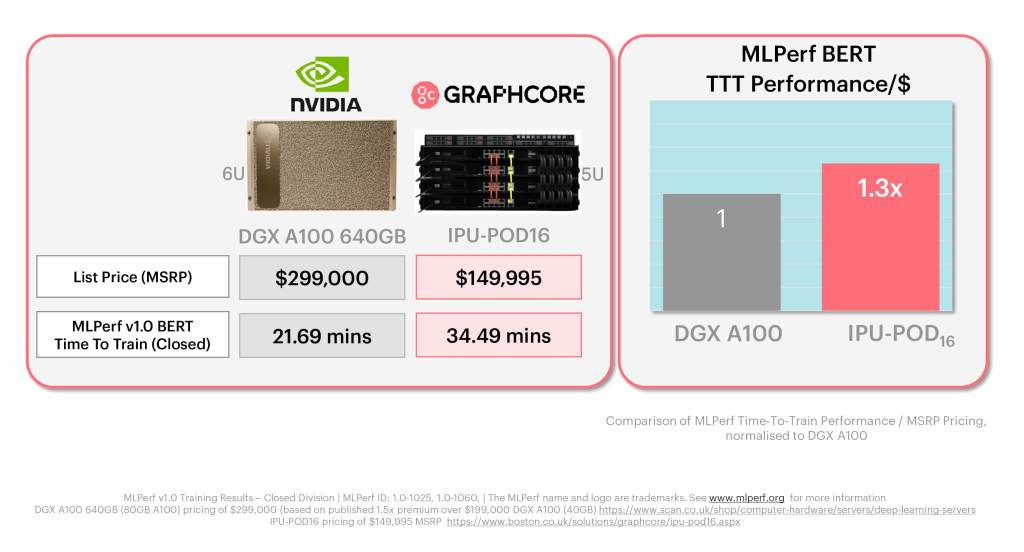
Graphcore created these marketing images to tout their results, but there are a variety of issues with the comparison.
They compared 16 of their TSMC fabricated 7nm 823mm^2 IPU’s vs 8 of Nvidia’s TSMC fabricated 7nm 826mm^2 A100’s. Comparing twice this silicon is quite disingenuous.
The Graphcore system has a much smaller memory capacity.
The Graphcore system is slower.
Graphcore specifically used 80GB A100’s rather than 40GB ones, which include a 1.5x price premium.
Graphcore specifically used Nvidia’s DGX systems which include tuned software libraries and direct Nvidia support instead of a off the shelf system from an OEM.
If we compare to an A100 system to a 3rd party commercially available SuperMicro system, the results look quite different. Instead of a 1.6x Price/$ advantage in ResNet model and 1.3x advantage in BERT model, we get a loss for Graphcore.

Graphcore wins turn into losses. These results look even worse as we scale up and compare to the 64 IPU system results. Graphcore’s list of disadvantages are the following.
Worse performance and performance/$
2x the 7nm silicon meaning much worse performance/mm^2
Issues with scaling to large models that require lots of AI silicon.
Issues with scaling up in processor count.
Far worse software support from framework and runtime support to performance tuning and deployment.
The Graphcore team is full of nice and smart people, but they are getting crushed. This AI startup that has been in the media and darling to many, but their seems valuation is very overblown. Their AI ASIC is worse at AI than Nvidia’s older GPU even when hand tuned. Even in power consumption, the IPU server only matches an 8x A100 SXM4 HGX-based server.
Nvidia has advantages in initial price/performance, TCO, and software while also delivering a far more versatile chip. Nvidia is also gearing up to replace the A100 with another GPU with over 2x the performance in AI within the first half next year. Graphcore cannot keep up with the existing Nvidia products and will be left in the dust by their relentless pace of execution. When we start talking about profitability, Graphcore looks even worse. Selling 2x the silicon for virtually the same price as Nvidia is not a winning formula.
This article was originally published on SemiAnalysis on July 1st 2021.
Clients and employees of SemiAnalysis may hold positions in companies referenced in this article.