



Marvell Acquires Tanzanite Silicon To Enable Composable Server Architectures Using CXL Based Memory Expansion And Pooling

Marvell continues their hot streak of amazing acquisitions by acquiring with the team over at Tanzanite. In just the last few years, Marvell has acquired Cavium, an Arm CPU and SOC specialist, Avera Semi, the storied IBM and GlobalFoundries custom ASIC unit, Inphi, a leader SerDes, TIAs, and DSPs, and Innovium, an up-and-coming scrappy fighter in the ethernet switch market. Tanzanite Silicon Solutions is much smaller than these other acquisitions, but it fills a very important hole in Marvell’s IP lineup. In all, it continues to increase Marvell's path to becoming the one stop shop for custom datacenter silicon solutions for the broader server market and cloud/hyperscale in-house efforts.
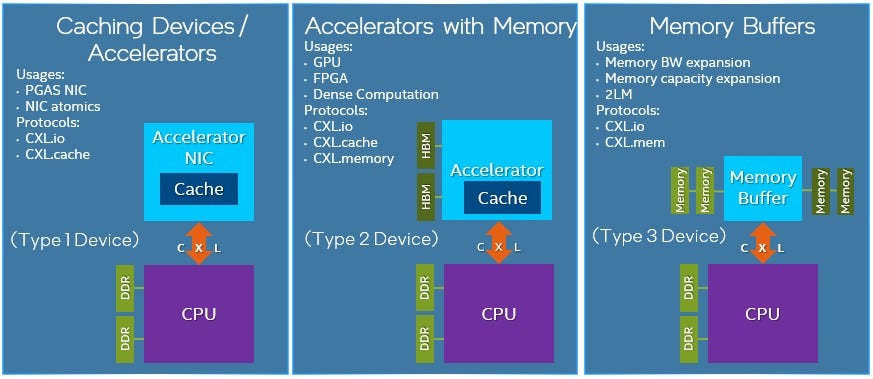
CXL is going to be a transformative technology due to its implementation as the standardized protocol for cache coherency and memory pooling. Tanzanite specifically is focused on memory pooling. Memory pooling is key as the industry move towards composable server architectures. We discussed this in our piece about Ayar Labs, but let's talk about it from the angle Marvell is going for.
Datacenters are an incredibly expensive affair. The capital expenditures required are massive, but the servers you build out with are not a homogenous blob. Workloads are not static. They are constantly growing and evolving. The mix of types of computational resources, DRAM, NAND, and networking shifts based on the workloads. A one size fits all model does not work, which is why you see cloud providers with dozens if not hundreds of different instance types. They try to optimize for differing workloads. Even then, many users end up paying for things they really don´t need.
Let's use the example of a simple server with only CPUs, ignoring any complexity related to accelerators. The vast majority of servers deployed seem simple initially. Grab a CPU, Intel or AMD, compatible motherboard, throw in some memory, storage, and networking. Done. Except that's not all. Your workload is going to greatly differ on the amount memory bandwidth or capacity it needs. Some workloads may only need a few cores but massive memory capacity, others may need tons of bandwidth and many cores, but no premium for capacity. The matrix of decisions begins to stack up massively.
This is where composable server architectures comes in. The core idea is that hardware dedicated to every workload in the cloud can be customized exactly for its exact needs. You access only the resources you want and nothing else. You no longer pay for the extra compute, storage, or most importantly DRAM. DRAM is by far the most expensive individual component of a server. Even though Intel Ice Lake and AMD Milan server CPUs support up to 4TB of memory, the most high volume configuration is 256GB per socket. To optimize the total cost of ownership, the DRAM capacity needs to minimized but still enable the processing requirements.
In any highly capital intense business, utilization rates are the most important factor to success. In semiconductor fabs for example, running at anything besides nearly maxed out, is very bad for profitability and long-term sustainability. DRAM in the server world has the same concept. Despite this fundamental fact of the business structure, cloud service providers do not have many levers to directly influence the utilization rates for DRAM within their datacenter. Each CPU has its DRAM memory directly attached to it via traditional memory channels. You slot in more or less memory when you build the server, or even upgrade it down the line, but that cannot be done on the fly as customers workloads shift.

Micron recently put out this estimate, and we agree with them whole heartedly. The future vision of composable server architectures where CPUs, memory, and storage are partially disaggregated is going to happen. It will need multiple revisions of the CXL standard, but the standards organization is fully committed, and the industry agrees this is the best path forward to improving cost structure.
This is where Tanzanite comes into the fold. Tanzanite has a “Smart Logic Interface Connector” (SLIC) SoC which enables independent scaling and sharing of memory and compute with low latency within and across servers. They are among the first companies to publicly demonstrate rack scale memory pooling across CXL. Astera Labs have also demonstrated similar technology, and Rambus is working on it too. We will talk about the progress of these companies has made including tape-out timelines in the subscriber only section. It is very likely that Samsung, SK Hynix, and Micron are also working on similar silicon, but there is no public confirmation. The DRAM vendors likely only focus on memory expansion, not pooling, for the short term
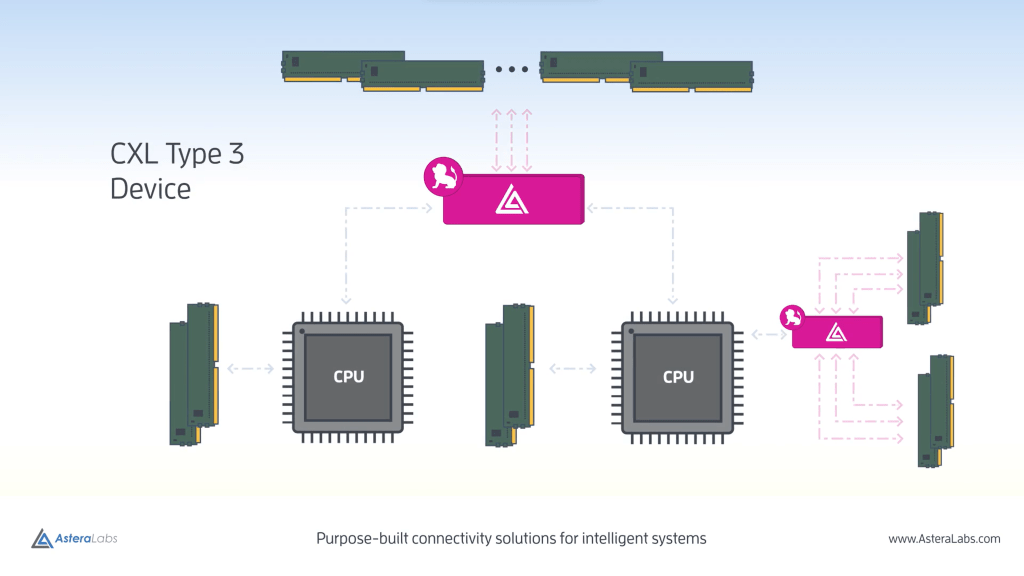
The current solutions for Tanzanite, Astera Labs, and Rambus are largely similar. They want to sell an ASIC that connects to other chips via CXL and then connects to standard DDR DIMMs. Tanzanite is specifically going for 32 lanes, which means 2Tbps of bidirectional bandwidth. Each of their 1st generation SLIC chips will contain 4 channels of DDR memory. The discussions we had with Tanzanite and the block diagram show off 4 CPUs connected to one SLIC ASIC. To clear up any confusion about the poor picture quality, I had permission to take cell phone pictures of their computer screen and show these images publicly, but was not able to get the direct high quality images.
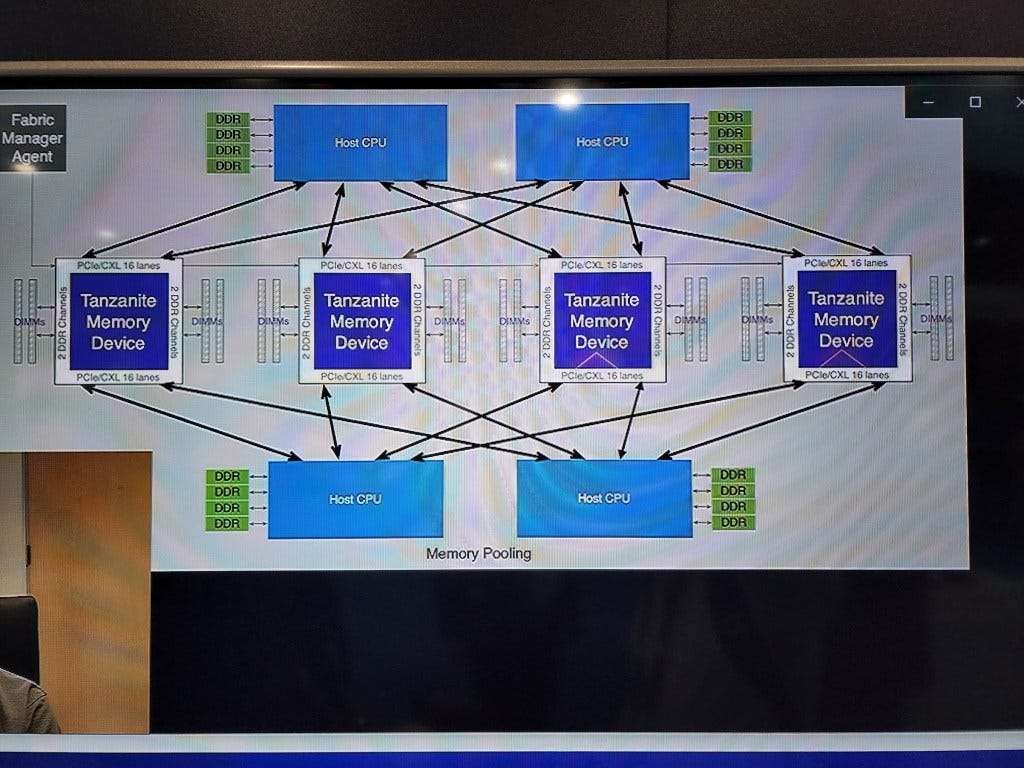
Here is a picture of the demo they were running in their office. Allocating memory to a CPU or removing it was quite seamless and quick. They were running the demo with Intel Sapphire Rapids CPUs and Intel FPGAs, but the ASIC is in the works.

Pooling memory has huge benefits in that you can remove and add only the amount of DRAM needed. There is a latency penalty, which is the biggest concern. This amounts to “CPU to CPU NUMA latency” as per Tanzanite. They wouldn’t give exact figures unfortunately, but we estimate round trip latency would be in the 250ns range versus 100ns to 150ns typically for Intel Ice Lake and AMD Milan accessing their local memory.

These CXL memory accelerators differ in that they offer the capability for pools of memory beyond just 1 CPU host. Samsung has created their own CXL memory modules, but they suffer from the fact that they can only connect to 1 node alone. They also come as a low volume custom product rather commodity unbuffered or registered DIMMs.
In short, Tanzanite allows Marvell to hit the ground running with one of the first CXL memory accelerators. Memory pools and composable server architectures are critical for overcoming bandwidth bottlenecks and capacity constraints. They should allow memory utilization rates to increase while also offering much lower total cost of ownership than using high capacity LRDIMMs in every server. In the paywalled section, we will talk about the tape out and production timelines for Tanzanite, Astera Labs, and Rambus. We will also talk about Tanzanite funding and motivation for selling.