


Meteor Lake Die Shot and Architecture Analysis – Why Is Intel 4 Only A 40% Area Reduction Versus Intel 7?
Meteor Lake Die Shot and Architecture Analysis – Why Is Intel 4 Only A 40% Area Reduction Versus Intel 7?

In this report, Locuza and SemiAnalysis will share and analyze a die shot of Intel’s Meteor Lake compute tile on the Intel 4 process node. With this die shot, we can analyze the various structures within the cores, caches, and fabric which we can use to determine that there is roughly only a 40% area reduction versus the Intel 7 node. This realized density improvement is very different from the 2x theoretical density gains that Intel has previously stated that the Intel 4 process node would have. Intel 4 is Intel’s first process technology with EUV and is supposed to mark Intel’s return to competing with TSMC on process technology. We will also be discussing the system architecture of Meteor Lake and Arrow Lake as well as the core architecture changes within the reworked Redwood Cove and Crestmont cores. Lastly, we will discuss the ramp timelines, competitive positioning, and some concerns about manufacturing costs. We have also created a YouTube video for those who want to watch and listen along.
Before getting into the nitty gritty details, we need to start a couple weeks ago and walk you through how we can do this analysis. Intel hosted their own conference called Vision, which covered a wide range of topics including current and upcoming products. SemiAnalysis was able to attend and have many great discussions with folks at Intel. One of the most interesting was when Pat Gelsinger flat out stated he would acquire more SAAS companies in response to a question from us. Other highlights included being able to check out some of Intel’s products and ask engineers technical questions in person. One of the highlights for us was the opportunity to take photos of various Intel products! Here I am clearly very happy holding some of Intel’s networking products, Tofino 2, Tofino 3, and the Mount Evans IPU (DPU). While we can’t speak to deeply of Tofino 3’s capabilities yet, it is the largest BGA package in the world. In other words, that’s a lotta silicon.

The most interesting physical thing at the show was silicon wafers. These included Alder Lake desktop CPUs, next generation Sapphire Rapids datacenter CPU, and next generation Meteor Lake compute tiles. The also showed off some test wafers from their Intel 20A and Intel 18A process technologies. While we did take a few pictures ourselves of Meteor Lake, our friends over at Comptoir-Harware were able to get some better ones! They were able to take the Meteor Lake wafer and zoom into a single die on the wafer. This image is the base of much of the analysis we will do. Carsten Spille also did a great job with the package image.
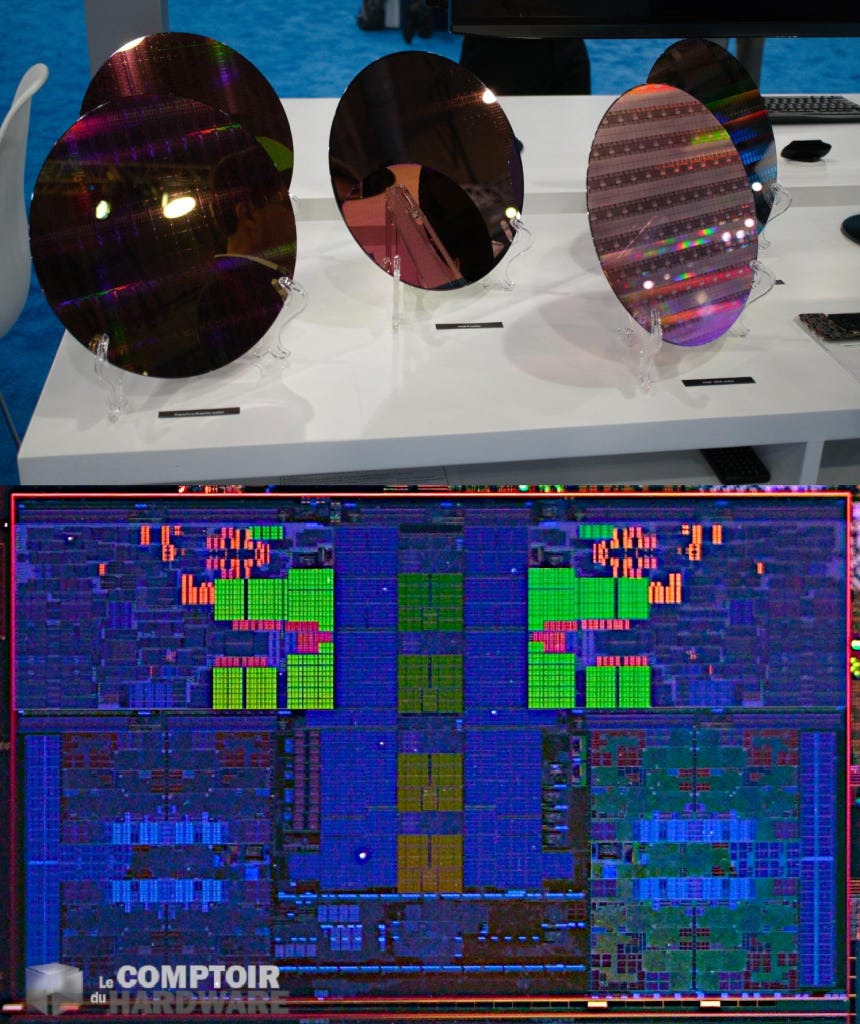
Using the first party and media images of the Meteor Lake wafer, packages, and video of the packaging process, we can determine the various die sizes of the chiplets used by Intel on Meteor Lake. The compute tile, which is comprised of various CPU core tiles as well as some of the associated fabric, is only a mere ~40mm2.
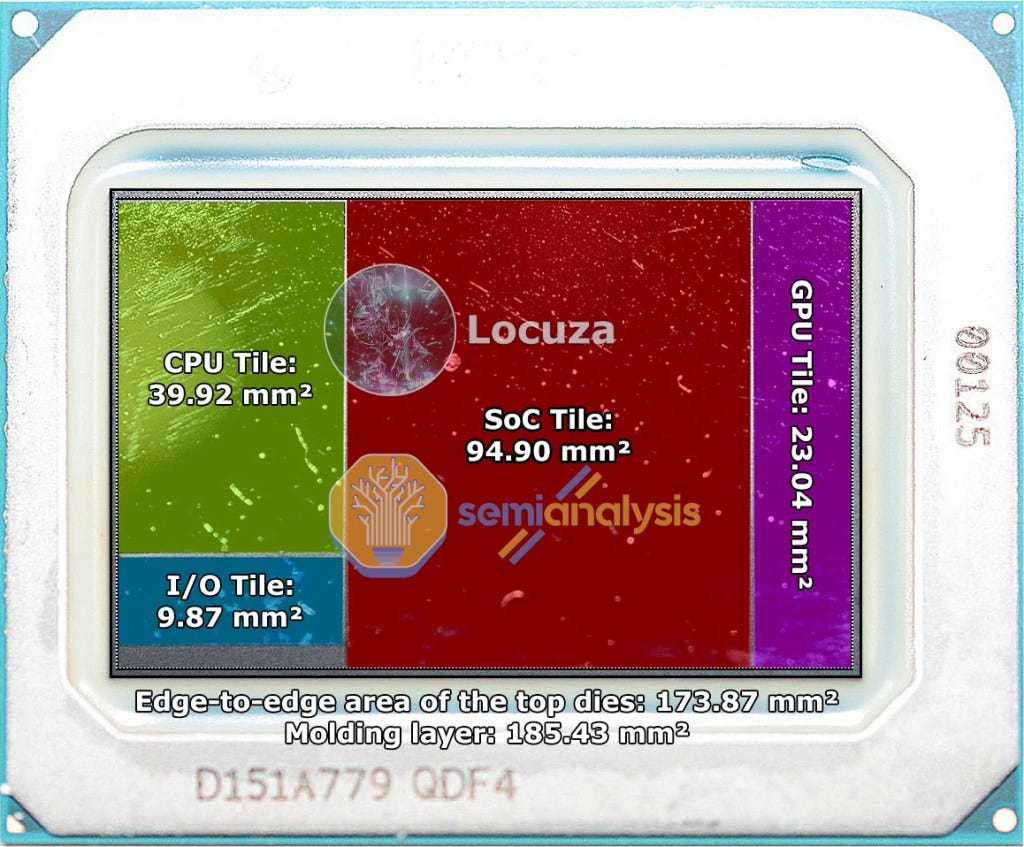
The other dies measure in at ~174mm2, ~10mm2, ~95mm2, and ~23mm2. The exact purpose of each of these dies is not confirmed, but we believe we believe they are for IO, SOC, and GPU. We will dive into each of these in their own section later in this article. First, let’s talk about the compute tile.
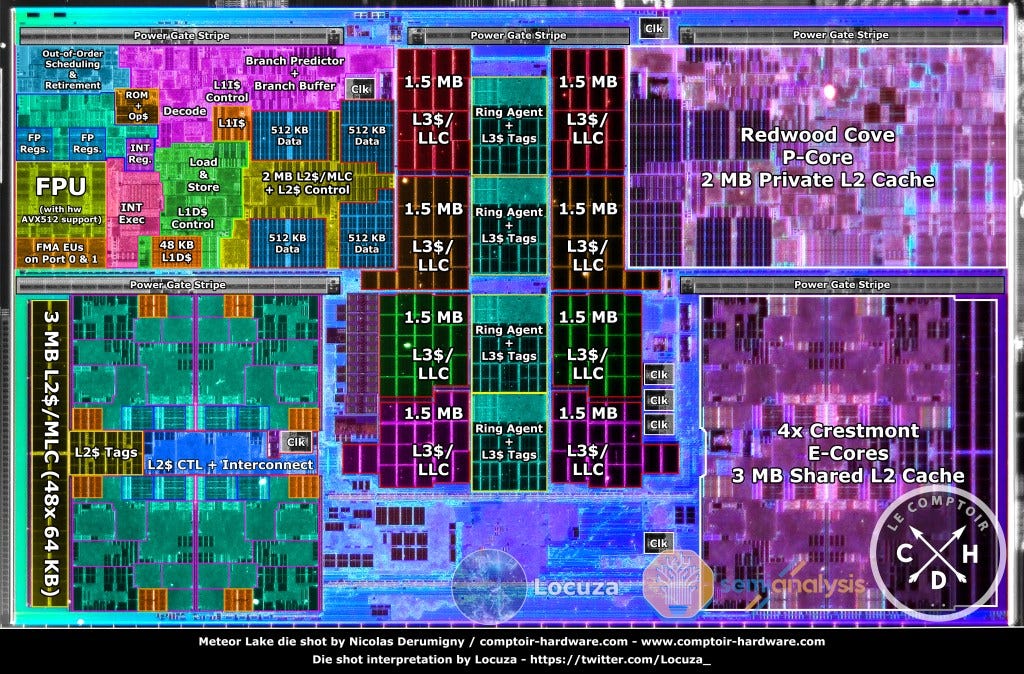
Locuza was able to identify and annotate most structures on the die including the 2 P Redwood Cove cores, 8 E Crestmont cores, and the last level cache which is attached to the ring bus. This is where we want to note that the analysis is not perfect, and there are some caveats. The Meteor Lake images are taken with a standard DLSR camera. Locuza was able to correct for some factors, like off axis tilt, but it’s still suboptimal and limits accuracy. These images are not the highest resolution given they were done on a show floor and not in a lab. There are also uncertainties for the scribe line margin and a few other factors. This leads us to believe the potential error margin for structures in the die shot in the mid to high single digits range. Not all structures and structure sizes are guaranteed to be 100% correct, but we believe we represent the physical layout design accurately. We will present the data exactly as measured.
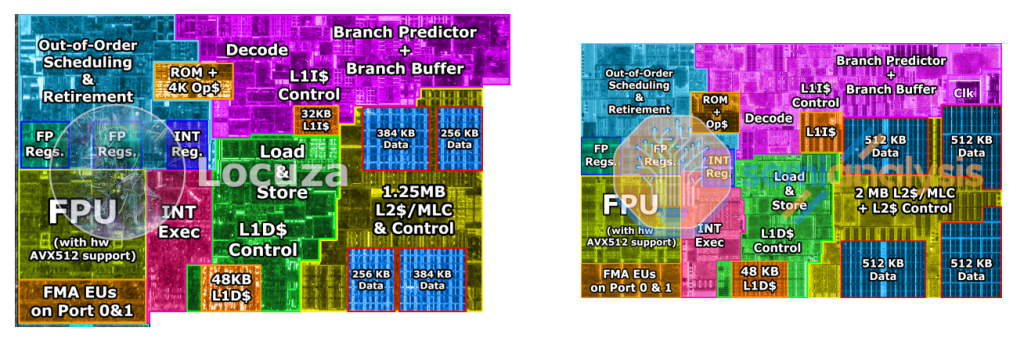
On the left is Golden Cove from the current generation Alder Lake, and on the right is Redwood Cove from Meteor Lake. From a high-level view Redwood Cove doesn't appear to shake things up dramatically, most subunits look very similar to before, without changing position or relative size proportions. In many structures, Redwood Cove is mostly a process technology shrink, but there are still quite a few immediately visible architectural changes that should help with IPC and performance.
For example, the L1 cache appears to be larger relatively (image analysis suggests 40KB to 45KB), so we believe it could have increased up from the current 32KB to 48KB. The L2 cache appears to have grown from 1.25MB to 2MB. This change in L2 cache also appears to be coming in Intel’s Raptor Lake which launches later this year. Intel likely did improve the Branch Prediction logic, although the buffer size seems to be (mostly) the same. This structure has been a frequent tweaking point for basically every core generation. The load & store buffers also seem larger, so one can expect a better memory subsystem. The area between the Out-of-Order region and Branch Prediction unit have few blocks which appear larger than before. The FPU design appears pretty much the same, and AVX512 seems to be relatively unchanged based on various software indicators for the instruction. FP and INT reg file also do not appear to be much larger, so we do not expect a large increase in entry size. Lastly, there were a few blocks which had their layout redesigned including SRAM placement to take more space vertically, instead of horizontally. We will need a first party architecture talk as well as in-depth micro-benchmarking from sites like Chips and Cheese to truly know what has changed.
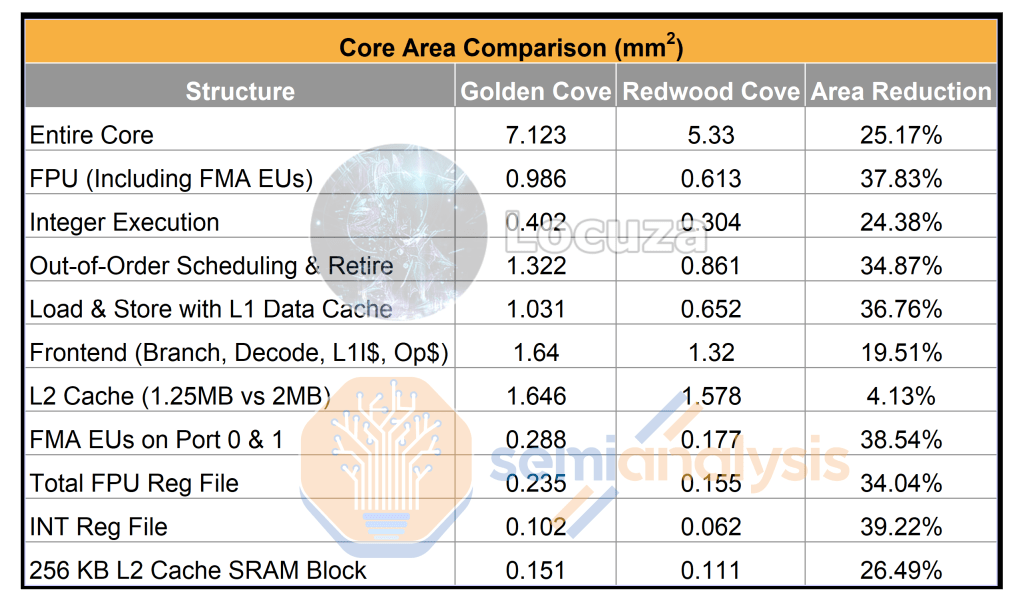
The area comparison is where things start to get spicy. The entire core had a ~25.17% reduction in total area (1.34x density improvement). The relative shrink differs across various blocks for a few reasons. One is that there is a clear architecture change across the two cores, and as such the comparison of total area is not an apples-to-apples comparison. Another reason is that SRAM and logic do not shrink by an equal amount, so even if the structures were identical, we would get different shrink factors based on the composition of the block. This is discussed in more detail when we were able to estimate of die sizes for Nvidia’s next generation Lovelace architecture based on specifications and simulations from the big Nvidia leak.
The most architecture-neutral comparison of pure process is the size difference between 256 KB of L2 cache on Intel 4 and Intel 7. Our data shows there is a 26.5% reduction in area (1.36x density improvement). The achieved shrink is fairly similar to Intel’s claim with their high-density SRAM cells despite the caveat that L2 cache likely uses higher performance SRAM cells and includes some logic such as assist circuitry. The highest individual subunit area reduction is the INT Reg File which is at nearly 40% (1.65x density improvement), so we have set this as the upper bound in terms of realized process density improvement. This fall quite short of a claimed 2x shrink.
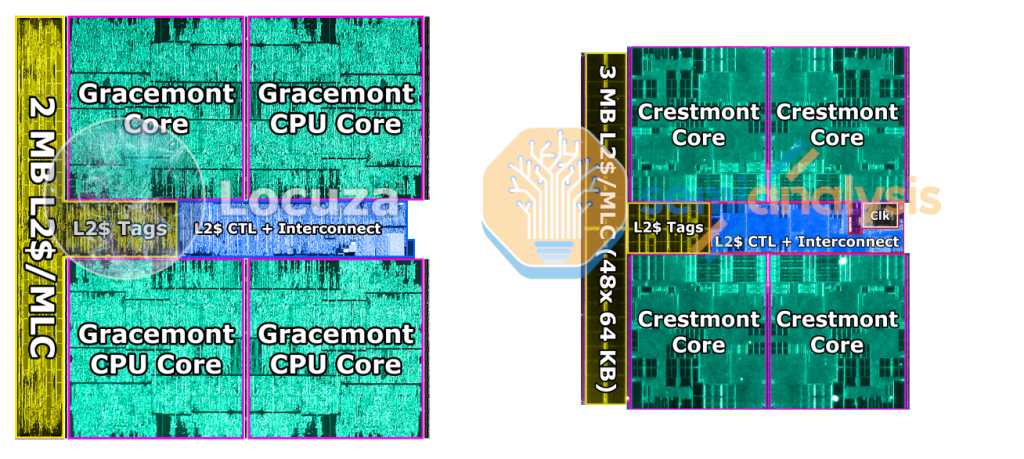
The other major structure on the compute tile that we can use for density comparisons is the E cores. On the left is Gracemont from Alder Lake and on the right is Crestmont from Meteor Lake. Architecturally, not much can be pulled out from this comparison besides that the L2 cache appears to be 3MB now instead of 2MB. Oddly, some leaks have suggested that Raptor Lake moves up to 4MB L2 on the E cores, which would place Meteor Lake’s 3MB in an odd middle ground. That detail of Raptor Lake is not confirmed.

Crestmont does not visually seem to have major architecture changes on the core. The area reduction of ~34% (1.52x density improvement) supports this claim. The shared L2 cache is composed of mostly SRAM and as such the shrink for this block is smaller. The total E core cluster has an area reduction of ~29% (1.4x density improvement). Golden Cove with its L2 cache is ~4.48x larger than Gracemont without the shared L2. The difference in size between these two cores is getting larger with Meteor Lake. Redwood Cove is ~5.1x larger than Crestmont. Intel’s strategy of E cores makes perfect sense to maximize performance per unit area of silicon.
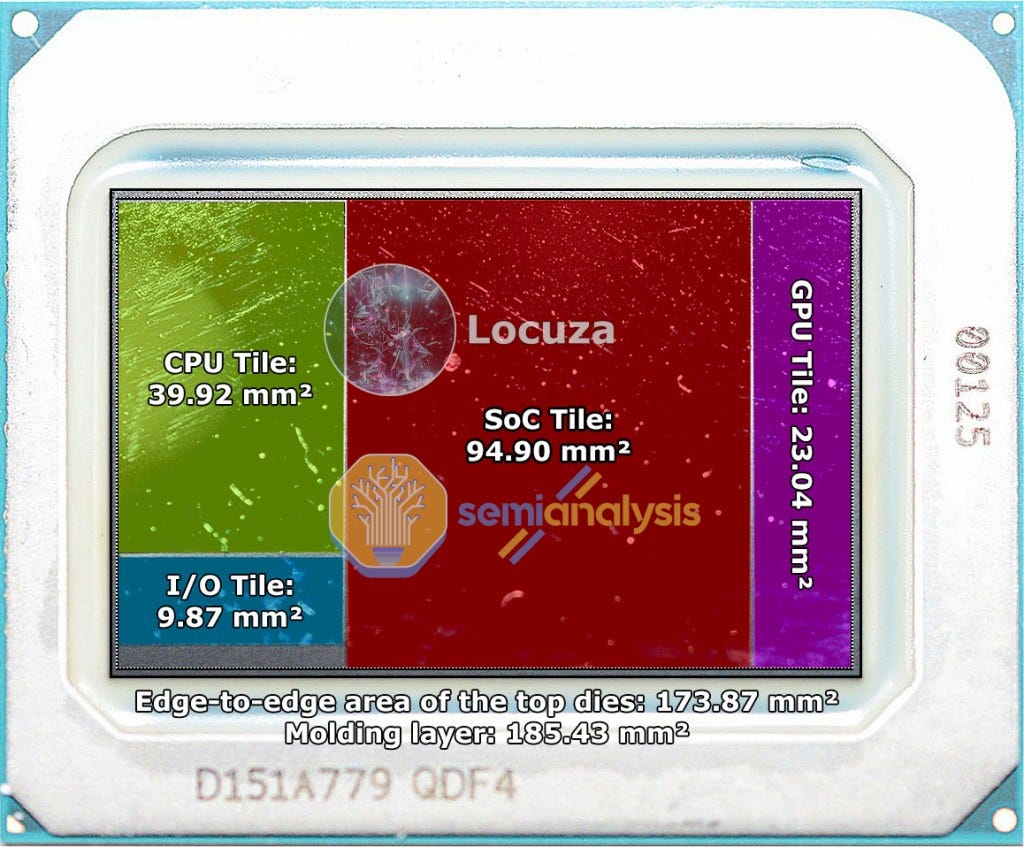
The CPU compute tile is only a tiny fraction of total silicon in Meteor Lake. Only the CPU tile is on the Intel 4 process node. The base tile is believed to be an active interpose using a lower cost and Foveros optimized variant of the Intel 7 node. This base tile should be active given Intel is branding it at Foveros, but it seems that Intel is leaving most of the base tile passive as the active elements seem to be on the other chiplets. The only function we can assign to this tile seems to be power delivery, capacitance, and connecting the various chiplets. The largest die on this chip is the “SOC” tile.
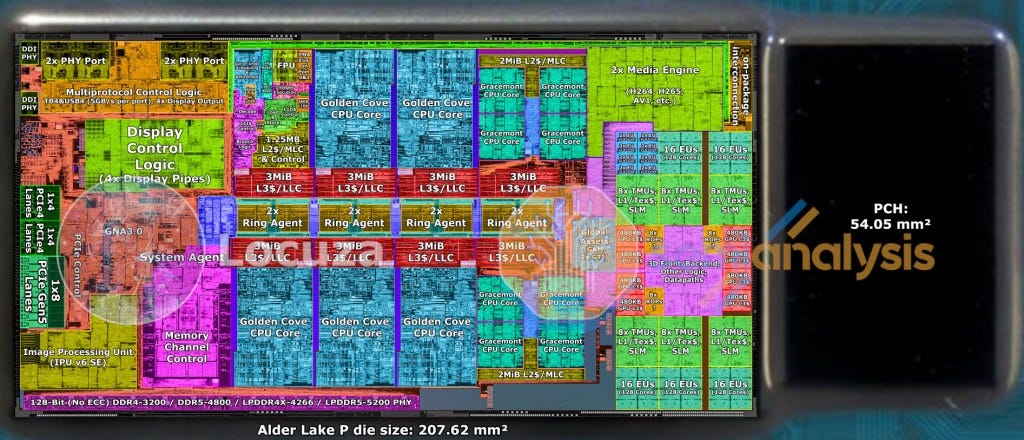
We believe the SOC tile is a combination of IP that is on the existing CPU die as well as the PCH. With Meteor Lake, there is no PCH/chipset. Currently PCH’s are built on a 14nm class process node as a way to reduce cost for additional IP. The PCH on Alder Lake mobile is 54mm2 and contains IP such as the IO needed for more PCIe lanes, USB ports, SATA, Intel Management Engine, and the digital logic needed for Wi-Fi. We believe all of this will also be included on the SOC tile. Furthermore, there is a variety of other logic currently on the CPU that could be moved there. The whole uncore area on the left side on Alder Lake P (TB4, Display PHYs, PCIe PHY, digital control logic, Image Processing Unit, GNA AI Accelerator, System Agent and Memory Controller) takes 55.9mm². The majority of this IP will be moved to the SOC tile, with some IP being moved to the 10mm² IO tile.
In total, we believe this is 54mm2 of 14nm and ~40mm2 of uncore Intel 7 silicon will be consolidated to the SOC die. . There will be some redundant area on the chipset, but given Intel likely enhances some of these IP blocks. All of this IP would fits nicely within the measured ~94.9mm2 of the SOC tile even if it is on a somewhat older node. Intel could use a 14nm or 16nm class node here again, but there have been some rumors that they may utilize a TSMC N6 node for this tile. The latter would make sense if the SOC tile has a low power Atom based island for connected standby, media complex, and VPU as some rumors have indicated. If these IP blocks are present on the SOC tiles, it would likely mean Meteor Lake has new power states and sleep states that could potentially dramatically save power. Edit 6/3/2022: We can confirm it is using the TSMC N6 process node.
With the 10mm² IO tile, we have heard conflicting rumors of what Uncore IP is located here. Some industry folks have suggested that Thunderbolt 4 and display engines are moved there, while others have suggested that the memory controller is located here. Both of these options are a possibility. The 4x Thunderbolt ports, display engines are about 20mm2 on Alder Lake P. Alder Lake P supports DDR4, DDR5, LPDD4x, and LPDDR5 and utilizes 16.7mm² which is split in about 6.8mm² for the I/O PHYs + interconnection and 9.9mm² for the memory controller.
Either of these IP blocks would a tight fit within the 10mm² I/O tile, but advanced packaging dramatically improving IO density and a more IP optimize process node could solve this. Furthermore, it is likely that Intel drops support for DDR4 and LPDDR4x which could save some area. Alder Lake M has 2 Thunderbolt ports while Alder Lake P (measured) has 4. Intel could keep 2 Thunderbolt ports on Meteor Lake M and drop down to 2 Thunderbolt ports on Meteor Lake P. There are some rumors the IO tile utilizes the TSMC process nodes, but we aren’t quite sure about that rumor yet. Such a dramatic increase in TSMC usage is hard to believe, but it is possible.
As far as GPU, Intel stated Meteor Lake will have from 96EU to 192EU of graphics. We believe the Meteor Lake that has been shown off includes 64EU or 96EU. GPU driver code seems to indicate the valid configurations are 64EU, 128EU, and 192EU while Intel slides show 96EU and 192EU. More on how Intel could be achieving 192EU in a bit. On Alder Lake, the 96EU and 2 media engines are a total of 42.5mm2 on the Intel 7 node. This area would likely grow more as you stack on various architecture changes that appear in Intel’s DG2 Alchemist GPUs such as AV1 encoding support, increase in instruction cache from 48KB to 96KB, increased vector register file from 28KB to 32KB, dedicated issue ports for floating point and integer ALUs, RT hardware, and 1024-bit matrix engines.
At first this may seem to be a tall order, but SemiAnalysis can confirm that Intel is utilizing TSMC’s N3B node for the Meteor Lake GPU tile. While we believe this is for all GPU tiles, it may only be fore the 192EU tile. If the 64/96 EU tile is indeed on N5/N4 instead of N3B, then the media engines would likely need to be on the SOC tile. With the shrink, it would be possible for 64/96EU to fit on the ~23mm2. N3B is a sizable shrink versus TSMC’s N5 which is already much denser than Intel 7. Some may question why TSMC would give wafer allocations for their most advanced nodes to Intel, but it makes sense. We also dove into that decision as well as what foundational IP Intel will get manufactured at TSMC last year.
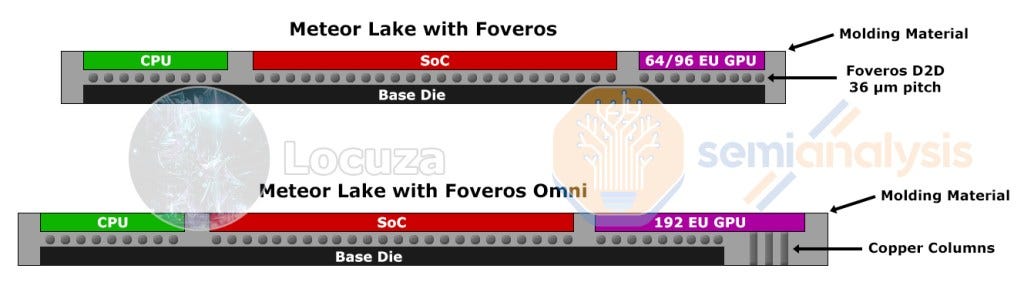
This is an illustrative drawing of what Intel could do to grow the GPU significantly beyond the size of what the Foveros interposer allows. As explained in our deep dive on advanced packaging, Foveros Omni would allow overhang and other enhancements to packaging especially in regards to power delivery and flexibility of design. This would be different packaging flow versus the standard Foveros which is a chip on wafer flow. That flow does not seem possible for Foveros Omni. Intel has stated before that Foveros Omni will go into production in 2023. Furthermore, they have said this is a client mobile product.
Our first Foveros Omni product is going to be a client product in the mobile segment.
Babak Sabi, SVP and GM of Assembly/Test Development at Intel
In terms of Meteor Lake rollout, this makes sense. Meteor Lake as a whole starts production in 2022, but that doesn’t mean every variant. Friends at OEMs have told us they get a lower GPU performance mobile CPUs first, but that there will be higher GPU performance mobile CPUs later in the year. Omni likely is reserved for the Arrow Lake SOC which shares many of the same system architecture details. We will discuss the rollout and ramp of Meteor Lake and Arrow Lake more in the subscriber only section.
With Foveros Omni, Intel could design a larger GPU with more execution units and package it in the same Meteor Lake P package. This GPU would have copper pillars to deliver power directly from the substrate and molding to assist with structural integrity. This method of advanced packaging allows Intel to sell smaller, cheaper GPUs where it makes sense, but not have to redesign as much silicon when they want to scale up to higher performance levels. It would require a redesigned packaging process flow, GPU tile, and substrate, but this is much cheaper than the alternative of redesigning everything. Foveros Omni could be a method for extending the CPU core counts as well, but we have not heard anything on how Intel plans to scale beyond 2P cores and 8E cores. We do know that Intel plans higher core count variants on both mobile and desktop.
The last piece of information we captured from Intel´s VisiON event is related to the final package of Meteor Lake. We took pictures of the bottom side of Meteor Lake. We will save you the pictures are they are quite boring, but the details we can glean from it are interesting.
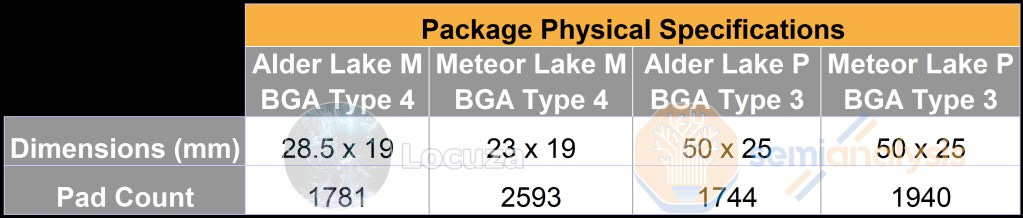
First off the M Type 4 package is much smaller for Meteor Lake. This is likely because Intel is chasing a much smaller form factor with this design. In the past, Intel has said Meteor Lake will scale all the way down from 5W to 125W. Currently, Alder Lake claims to scale down to 9W in the Type 4 package, but we haven’t seen any devices shipping in this configuration yet.
In addition to making the X and Y dimensions smaller, we believe Intel focused heavily on squeezing down the Z dimension as well. 5W to 10W class devices that are thin and performant on the x86 architecture could finally be realized due to this high-density package design. The Meteor Lake M package has a significantly higher number of pads versus Alder Lake M. While this could be due to more IO and reserved/unused, that’s not the only explanation. Our friends over at Angstronomics explained to us that more pads are needed with thinner and denser packages because they have less room to consolidate power and ground, meaning more dedicated pads to feed each specific region of the die. Tighter bump pitches also mean smaller solder pads which have less surface area and lower power transmission capability per pad, hence more pads are required.
Overall, Meteor Lake is an interesting architecture and design. It marks many first for Intel including mass volume Foveros (sorry, Lakefield and Ponte Veccio don’t count), EUV by using the Intel 4 process node, and implementation of TSMC’s N3B process node. It marks the complete redesign of the system architecture for Intel which will be mirrored in future architectures such as Arrow Lake. The chiplet tile architecture helps Intel proof and develop separate IP completely independently and even switch the IP out depending on product positioning and timelines as we discussed with the GPU.
The most groundbreaking or perhaps disappointing aspect of this Meteor Lake analysis is that Intel 4 only seems to have less than 40% area reduction (1.67x density improvement) versus Intel 7. While SRAM, logic, and analog tend to shrink at very different rates across process nodes, even the smallest subunits we could identify as identical seemed to fall very short of traditional full node theoretical scaling. As we showcased earlier, SRAM heavy IP like the 256KB L2 SRAM Block only seemed have a 26.5% reduction in area (1.36x density improvement).
Based on papers that Intel submitted to VLSI, Intel 4 has a 50nm gate pitch, 30nm fin pitch, 40nm min metal pitch, 16 metal layers, enhanced Copper at lower layers for lower line resistance, and 8 VT options (4N+4P). The high-density SRAM cell size is now 0.024um2 on Intel 4 vs 0.021um2 on TSMC N5 and 0.0312um2 on Intel 7. Intel is still behind the 2.5-year-old N5 process technology from TSMC in SRAM density even according to the official claims. Intel only achieved a 23.08% area reduction on their high-density SRAM cell (1.3x density improvement).
The problem of SRAM scaling is not independent to Intel either. A concrete example of poor SRAM scaling is with TSMC’s N5 process technology. TSMC quoted SRAM scaling as 1.35x versus 1.8x for pure logic. The breakdown of SRAM scaling has terrifying implications for the industry. Despite Intel 4 not appearing to be a full shrink on real world densities, it is still ahead of the 1.49x TSMC and Apple achieved from N7 to N5, and the 1.5x TSMC and Nvidia achieved from N7 to N5. As such, the Intel shrink does appear seem to be a full node scaling within the paradigm of SRAM scaling issues. The Intel 4 process node name moniker is a bit odd though given TSMC N5’s high density SRAM actually has a 1.14x density improvement versus Intel 4.
The last thing we want to discuss is the ramp timelines and size, competitive positioning versus AMD Phoenix and Strix, and manufacturing costs related to Meteor Lake and her successor Arrow Lake. This will be done in the subscriber only section. Locuza and SemiAnalysis are completely ad free and independently supported directly by our subscribers and consulting arrangements, so we would love if you subscribed to either one of us, or both of us. Locuza did most of the work regarding measurements and area, so please support him by giving him a follow on Twitter, subscribing on YouTube, and a few bucks on Patreon.