



Nvidia’s Optical Boogeyman – NVL72, Infiniband Scale Out, 800G & 1.6T Ramp
Transceiver to GPU Ratio, DSP Growth, Revealing The Real Boogeyman


At GTC, Nvidia announced 8+ different SKUs and configurations of the Blackwell architecture. While there are some chip level differences such as memory and CUDA core counts, most of the configurations are system level such as form factor, networking, CPU, and power consumption. Nvidia is offering multiple 8 GPU baseboard style configurations, but the main focus for Nvidia at GTC was their vertically integrated DGX GB200 NVL72.
Rather than the typical 8 GPU server we are accustomed to, it is a single integrated rack with 72 GPUs, 36 CPUs, 18 NVSwitches, 72 InfiniBand NICs for the back end network, and 36 Bluefield 3 Ethernet NICs for front end network.

Optics and the GB200 NVL72 Panic
When Nvidia’s DGX GB200 NVL72 was announced in the keynote speech last week – with the capability of linking 72 GPUs in the same rack with 900GB/s per GPU NVLink 5 connections – panic set in. Tourists in various optical markets began to run for the hills after reacting quite violently to Jensen’s words.
And so we have 5,000 cables, 5,000 NVLink cables. In total, 2 miles. Now this is the amazing thing. If we had to use optics, we would have had to use transceivers and retimers. And those transceivers and retimers alone would have cost 20,000 watts, 20 kilowatts of just transceivers alone, just to drive the NVLink spine. As a result, we did it completely for free over NVLink switch and we were able to save the 20 kilowatts for computation.
Jensen Huang

These skittish observers saw the NVLink scale up to 72 GPUs over 5,184 direct drive copper cables as the optical boogeyman come to spoil the various optical supply chain players. Many have argued that because the NVLink network connects all 72 GPUs in the rack, you need fewer optics to achieve connectivity for GPUs within a cluster. These optical tourists thought the optical intensity, IE number of optical transceivers required per Nvidia GPU clusters, would go down meaningfully.
This is false, and they misunderstood Jensen’s words. The number of optics does not go down.
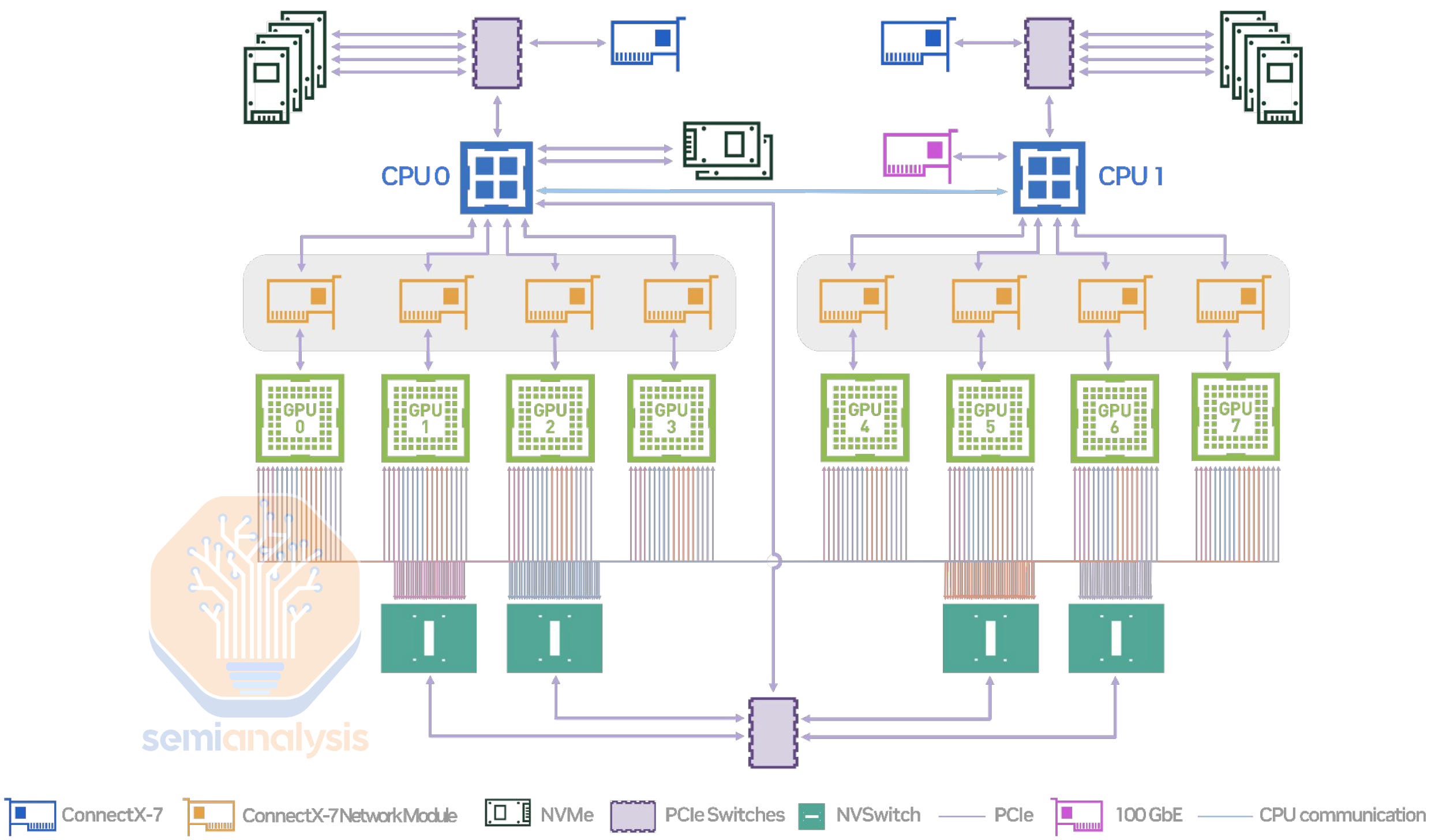
The DGX H100 and DGX GB200 NVL utilize three distinct networks. A front end network running Ethernet with a ratio of 2 or 4 GPUs per NIC, a back end scale out InfiniBand or Ethernet network running at 400G or 800G, depending on the configuration, but always with a ratio of 1 NIC per GPU, with another back end scale up NVLink network linking all 8 or 72 GPUs together.

For the back end scale out network – the NVL72 rack showcased at GTC still has 72 OSFP ports at 400G / 800G – one for each GPU – which is exactly the same connectivity implemented in the H100 – i.e. the same ratio of optical transceivers to GPUs. As GPU network sizes scale, the number of optical transceivers required also scales.

The only scenario in which you do not populate transceivers into the 72 OSFP ports on the GB200 NVL72 is if you plan to only buy one rack of the GB200 NVL72. To be clear, no one is buying only 1 rack, as they’d be better off buying 8 GPU baseboards instead. Second, deployment flexibility is everything, and while you may intend a server or rack for one purpose in the short term, that purpose will change over time, and as such ratios change.
The NVL72 is not the optical boogeyman people should worry about, there is another, much more real optical boogeyman.
This optical boogeyman dramatically reduces the number of transceivers by a significant volume, and it’s shipping in volume next year. Below we will explain what, how, and by how much.