



On Device AI – Double-Edged Sword
Scaling limits, model size constraints, why server based AI wins, and future hardware improvements


The most discussed part of the AI industry is chasing ever-larger language models that can only be developed by mega-tech companies. While training these models is costly, deploying them is even more difficult in some regards. In fact, OpenAI’s GPT-4 is so large and compute-intensive that just running inference requires multiple ~$250,000 servers, each with 8 GPUs, loads of memory, and a ton of high-speed networking. Google takes a similar approach with its full-size PaLM model, which requires 64 TPUs and 16 CPUs to run. Meta’s largest recommendation models in 2021 required 128 GPUs to serve users. The world of ever more powerful models will continue to proliferate, especially with AI-focused clouds and ML Ops firms such as MosaicML assisting enterprises with developing and deploying LLMs…but bigger is not always better.
There is a whole different universe of the AI industry that seeks to reject big iron compute. The open-source movement around small models that can run on client device is probably the 2nd most discussed part of the industry. While models on the scale of GPT-4 or the full PaLM could never hope to run on laptops and smartphones, even with 5 more years of hardware advancement due to the memory wall, there is a thriving ecosystem of model development geared towards on-device inference.
Today we are going to discuss these smaller models on client-side devices such as laptops and phones. This discussion will focus on the gating factors for inference performance, the fundamental limits to model sizes, and how hardware development going forward will establish the boundaries of development here.
Why Local Models Are Needed
The potential use cases for on-device AI are broad and varied. People want to break free of the tech giants owning all their data. Google, Meta, Baidu, and Bytedance, 4 of the 5 leaders in AI, have basically their entire current profitability predicated on using user data to target ads. Look no further than the entire IDFA kerfuffle as to how important the lack of privacy is for these firms. On-device AI can help solve this problem while also enhancing capabilities with unique per-user alignment and tuning.
Giving smaller language models the performance of last-generation large models is one of the most important developments over the last few months of AI.
A simple, easily solved example is that of on-device speech-to-text. It is quite bad, even from the current class-leading Google Pixel smartphones. The latency from going to the cloud-based models is also very jarring for natural usage and depends heavily on a good internet connection. The world of on-device speech-to-text is rapidly changing as models such as OpenAI Whisper run on mobile devices. (Google IO also showed these capabilities may be upgraded massively soon.)
A bigger example is that of Siri, Alexa, etc, being quite horrible as personal assistants. Large language models with the assistance of natural voice synthesizing AI could unlock far more human and intelligent AI assistants that can assist with your life. From creating calendar events to summarizing conversations to search, there will be a personal assistant on every device based on a multi-modal language model. These models are already far more capable than Siri, Google Assistant, Alexa, Bixby, etc, and we are still in the very early innings.
In some ways, generative AI is rapidly becoming a bimodal distribution with massive foundational models and much smaller models that can run on client devices, garnering the majority of investment and a great chasm in between.
The Fundamental Limits of On-Device Inference
While the promise of on-device AI is undoubtedly alluring, there are some fundamental limitations that make local inference more challenging than most anticipated. The vast majority of client devices do not and will never have a dedicated GPU, so all these challenges must be solved on the SoC. One of the primary concerns is the significant memory footprint and computational power required for GPT-style models. The computational requirements, while high, is a problem that will be solved rapidly over the next 5 years with more specialized architectures, Moore’s Law scaling to 3nm/2nm, and the 3D stacking of chips.
The highest-end client mobile devices will come with ~50 billion transistors and more than enough TFLOP/s for on-device AI due to architectural innovations that are in the pipeline at firms like Intel, AMD, Apple, Google, Samsung, Qualcomm, and MediaTek. To be clear, none of their existing client AI accelerators are well-suited for transformers, but that will change in a few years. These advancements in the digital logic side of chips will solve the computing problem, but they cannot tackle the true underlying problem of the memory wall and data reuse.
GPT-style models are trained to predict the next token (~= word) given the previous tokens. To generate text with them, you feed it the prompt, then ask it to predict the next token, then append that generated token into the prompt, then ask it to predict the next token, and keep on going. In order to do this, you have to send all the parameters from RAM to the processor every time you predict the next token. The first problem is that you have to store all these parameters as close as possible to the compute. The other problem is that you have to be able to load these parameters from compute onto the chip exactly when you need them.
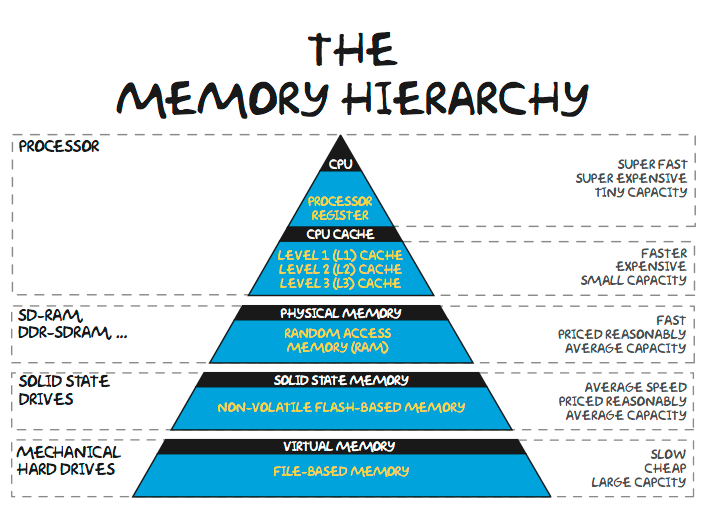
In the memory hierarchy, caching frequently accessed data on chip is common across most workloads. The problem with this approach for on-device LLM is that the parameters take too large of memory space to cache. A parameter stored in a 16-bit number format such as FP16 or BF16 is 2 bytes. Even the smallest “decent” generalized large language models is LLAMA at a minimum of 7 billion parameters. The larger versions are significantly higher quality. To simply run this model requires at minimum 14GB of memory at 16-bit percision. While there are a variety of techniques to reduce memory capacity, such as transfer learning, sparsification, and quantization, these don’t come for free and do impact model accuracy.
Furthermore, this 14GB ignores other applications, operating system, and other overhead related to activations/kv cache. This puts an immediate limit on the size of the model that a developer can use to deploy on-device AI, even if they can assume the client endpoint has the computational oomph required. Storing 14GB of parameters on a client-side processor is physically impossible. The most common type of on-chip memory is SRAM, which even on TSMC 3nm is only ~0.6GB per 100mm^2.
For reference, that is about the same size chip as the upcoming iPhone 15 Pro’s A17 and ~25% smaller than the upcoming M3. Furthermore, this figure is without overhead from assist circuity, array inefficiency, NOCs, etc. Large amounts of local SRAM will not work for client inference. Emerging memories such as FeRAM and MRAM do bring some hope for a light at the end of the tunnel, but they are quite far away from being productized on the scale of Gigabytes.
The next layer down the hierarchy is DRAM. The highest-end iPhone, the 14 Pro Max, has 6GB of RAM, but the modal iPhone has 3GB RAM. While high-end PC’s will have 16GB+, the majority of new sales are at 8GB of RAM. The typical client device cannot run a 7 billion parameter model quantized to FP16!
This then brings up the question. Why can’t we go down another layer in the hierarchy? Can we run these models off of NAND-based SSDs instead of off RAM?
Unfortunately, this is far too slow. A 7 billion parameter model at FP16 requires 14GB/s of IO just to stream the weights in to produce 1 token (~4 characters)! The fastest PC storage drives are at best 6GB/s, but most phones and PCs come in south of 1GB/s. At 1GB/s, at 4-bit quantization, the biggest model that can be run would still only be in the range of ~2 billion parameters, and that’s with pegging the SSD at max for only 1 application with no regard for any other use-case.
Unless you want to be stuck waiting 7 seconds for half a word to be spit out on the average device, storing parameters in storage is not an option. They must be in RAM.
Limit On Model Size
The average person reads at ~250 words per minute. As a lower bound for good user experience, an on-device AI must generate 8.33 tokens per second, or once every 120ms. Skilled speed readers can reach 1,000 words per minute, so for an upper bound, on-device AI must be capable of generating 33.3 tokens per second, or once per 30ms. The chart below assumes the lower bound of average reading speed, not speed reading.

If we conservatively assume normal, non-AI applications as well as activations/kv cache consume half of all bandwidth, then the largest feasible model size on an iPhone 14 is ~1 billion FP16 parameters, or ~4 billion int4 parameters. This is the fundamental limits on smartphone-based LLMs. Any larger would exclude such a large part of the installed base, that it wouldn’t be able to be adopted.
This is a fundamental limit on how large and powerful local AI can get. Perhaps a company like Apple can use that to upsell newer, more expensive phones with more advanced AI, but that is still a while away. With the same assumptions as above, on PC, Intel’s top-of-the-line 13th generation i9 CPUs and Apple’s M2 are capped out at about ~3 to ~4 billion parameters.
In general, these are just the lower bounds for consumer devices. To repeat, we ignored multiple factors, including using theoretical IO speed, which is never achieved or activations/kv cache for simplicity sake. Those only push BW requirements up more, and constrain model size down further. We will talk more below about innovative hardware platforms that will come next year that can help reshape the landscape, but the memory wall limits the majority of current and future devices.
Why Server-Side AI Wins
Due to the extreme memory capacity and bandwidth requirements, generative AI is affected by the memory wall more than any other application before it. On client inference, with generative text models, there is almost always a batch size of 1. Each subsequent token requires the prior tokens/prompt to be inputted, meaning every time you load a parameter onto the chip from memory, you only amortize the cost of loading the parameter for only 1 generated token. There are no other users to spread this bottleneck with. The memory wall also exists on server-side compute, but each time a parameter is loaded, it can be amortized over multiple generated tokens for multiple users (batch size).
Our data shows that HBM memory is nearly half the manufacturing costs of a server-class AI chip like the H100 or TPUv5. While client-side compute does get to use significantly cheaper DDR and LPDDR memory (~4x per GB), that memory cost cannot be amortized over multiple concurrent inferences. Batch size cannot be pumped to infinity because that introduces another difficult problem, which is that any single token has to wait for every other token to be processed before it can append its results and work on the generation of the new token.

This is solved by splitting the model across many chips. The above chart is the latency for generating 20 tokens. Conveniently, the PaLM model hits the 6.67 tokens per second, or a ~200 words per minute minimum viable target, with 64 chips running inference at a batch size of 256. This means each time a parameter is loaded, it is utilized for 256 different inferences.
FLOPS utilization improves as batch size increases because the memory wall is being mitigated. Latency can only be brought to a reasonable point by splitting the work across more chips. With that said, even then, only 40% of FLOPS are even used. Google demonstrated 76% FLOPS utilization with a latency of 85.2 seconds for PaLM inference, so the memory wall is still clearly a massive factor.
So server side is far more efficient, but how far can local models scale?
Client-side Model Architecture Evolution & Hardware Advancements
There are a variety of techniques to try to increase the number of parameters a model on the client side can use. Furthermore, there are some interesting hardware developments coming from Apple and AMD specifically, which could help with scaling further.
This post is for paid subscribers
 | A guest post by
|