

Peeling The Onion’s Layers - Large Language Models Search Architecture And Cost
Ad Engine, Crawl, Index, and Query Processing disrupted by LLMs


Last week we dove into the cost of chatGPT and the potential disruption of the search business by Microsoft Bing and OpenAI leveraging large language models (LLMs). That piece is basically required reading for this one, but the takeaway is that ChatGPT currently costs ~$700,000 a day to operate in hardware inference costs. If the current implementation and operation of ChatGPT were ham-fisted into every Google Search, it would represent a tremendous increase in cost structure to the tune of $36 billion. Google’s annual net income for their services business unit would drop from $55.5 billion in 2022 to $19.5 billion.
This is never going to happen, of course, but fun thought experiment if we assume no software or hardware improvements are made.
The Inference Cost Of Search Disruption – Large Language Model Cost Analysis
The first round of optimization is simple. Token output counts for 84 different real examples of Bing GPT were significantly lower, ~350, vs. the 2,000 used for ChatGPT. In most cases, people want to avoid reading huge chunks of information when interacting with search. This estimate accounts for tokens that are not displayed to the user. The subsequent optimization is that the top 2,000 keywords account for 12.2% of searches, and many more are also purely navigational searches. Let’s assume that 20% of searches will not require an LLM. Lastly, Google has significant infrastructure advantages using the in-house TPUv4 pods versus Microsoft/OpenAI using Nvidia-based HGX A100s.
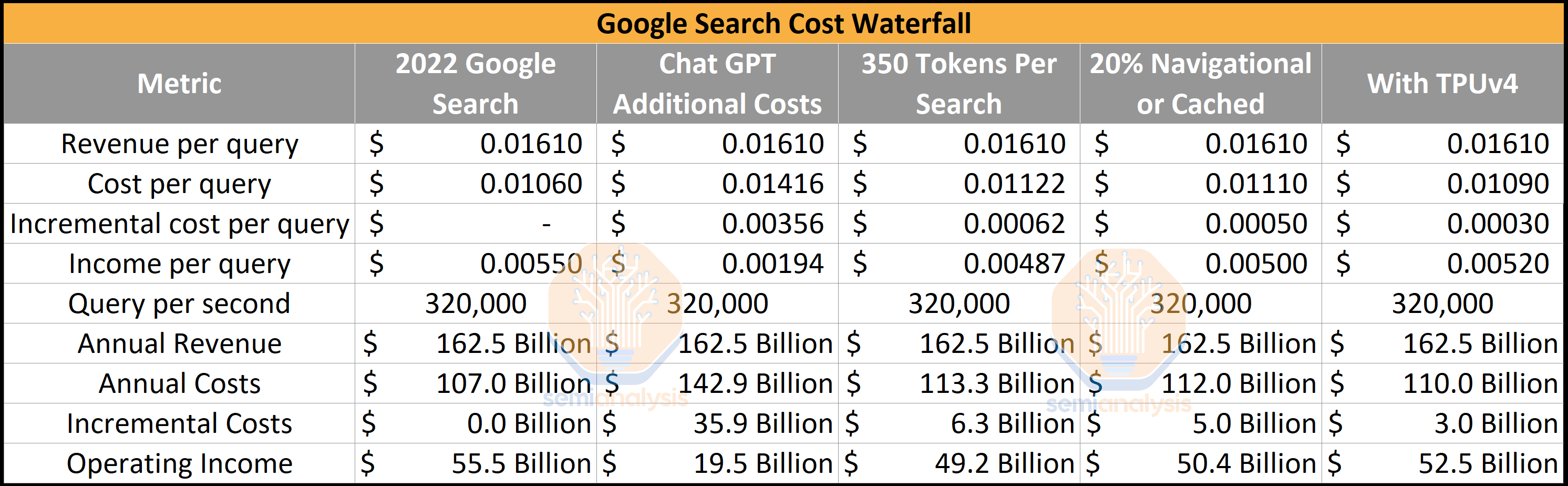
These simple optimizations bring the additional costs for implementing an LLM into search to only $3 billion for Google. The Capex costs for Google on the hardware alone would be on the order of ~$20B, including datacenter infrastructure, if everything was set up perfectly from the get-go. This is before new hardware such as Nvidia H100 and Google’s TPUv5 or various techniques such as MoE, sparsity, pruning, model distillation, kv cache, and early exit improve costs.
People are not going to accept an interface to an internet-connected ChatGPT. It’s too slow, prone to making up information, and cannot be monetized effectively. The above analysis is still overly simplistic and only accounts for LLMs in 1 part of the search stack, real-time query processing.
Today we will dive into the future implementations of LLMs within the entire search stack. The unit revenue economics and cost structure will be reworked entirely due to the shifts in user experience, which will rapidly change over the next 2 to 3 years.
To go deeper into the changes coming from both a revenue and cost perspective, we first must explain the current search architecture as it gives context to the changes for the future. From a high level, the goal of search is to provide relevant information as quickly as possible. When you enter keywords, you want the best information lifted to the top. The search pipeline has four major processes: the crawler, index, query processor, and ad engine. Machine learning models are already used extensively in all four.
Crawler
The crawler automatically locates new content on the internet, including web pages, images, and videos, and adds it to the search engine's database (index). By utilizing machine learning, the crawler determines the worthiness of pages to be indexed and identifies duplicate content. It also analyzes the links between pages, assessing which pages are likely relevant and significant. This information is used to optimize the crawling process, determining which pages to crawl, how often, and to what extent.
The crawler also plays a significant role in content extraction. The goal is to comprehensively textualize what a webpage contains while minimizing the total size of that data to support fast and accurate searches. Latency is everything in search, and even a few hundred milliseconds significantly impact how much users search.
Google and Bing utilize image and small language models to generate metadata that is not inherently on the page/image/video. The obvious insertion point for large language and multi-modal models is massively extending these capabilities. This is not contemplated in any simplistic model of search costs. We will discuss the use case and estimate costs later in this report.
The Index
The index is a database that stores information that the crawler discovered. A significant amount of preprocessing is done in the index layer to minimize the data volume that must be searched. This minimizes latency and maximizes search relevance.
Relevance ranking: Models can be used to rank the pages in the index based on relevance so that the most relevant pages are returned first in response to a user's search query.
Clustering: Models can be used to group similar pages in the index into clusters, making it easier for users to find relevant information.
Anomaly detection: Models can detect and remove anomalous or spammy pages from the index, improving the quality of the search results.
Text classification: Models can be used to classify the pages in the index based on their content and context.
Topic modeling: Models can identify the topics covered by the index pages and map each page to one or more topics.
While this is currently done with smaller models and DLRMs, the effectiveness would significantly increase if LLMs are inserted. This is not contemplated in any simplistic model of search costs. We will discuss the use case and estimate costs later in this report.
Query Processor
This has been the layer of the search stack that has been most under focus. It receives the user’s queries and generates the most relevant results. It does this by parsing the user’s query, breaking it down into keywords and phrases, grabbing the most relevant items from the index, then reranking and filtering for that user’s specific query. The query processor is also in charge of presenting these results to the user.
There are currently multiple models deployed in this pipeline, from simplistic spell-checking to query expansion which automatically adds related terms to a user's query to improve the accuracy of the search results. Relevance ranking and personalizing results based on the user's search history, location, device, preferences, and interests. This currently requires running inference on multiple small models.
Query processing must be performed quickly and efficiently, as users submit queries in real time. In contrast, crawling and indexing are ongoing processes that occur continuously and do not interface with the user.
As an aside, Google and Bing use very different hardware for their classical approaches here. Google uses a lot of standard CPUs and in-house TPUs. On the other hand, Bing currently uses many standard CPUs and FPGAs. The FPGAs accelerate both rankings and AI.
Ad Engine
While the last three parts of the search stack are critical for satisfying and retaining users, many consider the ad engine the most important, as all monetization stems from its quality. The query processor interacts with the ad engine in real time. The ad engine must model the relationships between user queries, user profiles, location, and advertisement performance to generate personalized recommendations for each user that maximize click-through rates and revenue.
The ad market is a real time bidding bonanza where advertisers generally pay for keywords, phrases, or certain user types. The ad model uses those loosely as guidelines because the amount paid is not the only metric for serving. The model needs to optimize conversion to earn revenue and drive up rates, so relevance is the hyper-optimized parameter.
On average over the past four years, 80 percent of searches on Google haven’t had any ads at the top of search results. Further, only a small fraction of searches--less than 5 percent--currently have four top text ads.
With LLMs, the part the consumer reads is not the first few results where the ad can be converted to a sale for the advertiser. Instead, it is the output of the LLM. As such, this is part of the search stack that will change the most with the advent of conversational LLMs. We will discuss how and what happens to monetization later in this report because this is a fundamental shift in how ad serving must operate.
The Radical Shift
LLMs within search are not just one big model ham-fisted into a search engine’s interface. Instead, it is many models interlaced. Each model’s job is to give the next model in the chain the densest and most relevant information possible. These models must be constantly re-trained, tuned, and tested on active users. Google historically pioneered the use of AI within all four layers of the search stack, but now, search is undergoing a fundamental shift in user experience, usage models, and monetization structure which may invalidate many existing portions of the software stack.
The biggest question is if Google is culturally up for the task. Google has to protect its golden egg. Can they adapt their entire search stack?
Move fast and break things.
Mark Zuckerburg, 2011
Does Google have a cultural requirement to hyper-optimize its search stack before the usage models are figured out? Suppose Google puts too many resources into operating at the lowest cost and reaches a local maxima for search relevance. In that case, Google could be lost in the weeds and limit its model development and innovations that should have been dedicated to expanding and testing new usage models. The Microsoft and OpenAI teams are more likely to push caution aside and test out radical reworks of all four elements of the search stack.
The most obvious example of Google playing it too safe and optimizing too early is with their search competitor, Bard.
We’re releasing it initially with our lightweight model version of LaMDA. This much smaller model requires significantly less computing power, enabling us to scale to more users, allowing for more feedback.
They are cutting down a model whose architecture was developed initially in early 2021. Of course, it has improved since, but OpenAI and Microsoft are using a larger model and newer architecture developed in late 2022 and early 2023 with continuous feedback from ChatGPT. There is a legitimate reason for this, but also it is the one that may get Google bulldozed on user experience and less valuable iterative speed.
Even more worrisome is the recent trickle of some visionary talents leaving for startups, including but not limited to OpenAI, over the last few months. This includes the godfather of BERT, the lead engineer for PaLM inference, and a lead engineer for Jax. This could be a sign of weakening culture.
Imagine if this search competition causes Google’s stock to continue falling and RSUs are worth much less than expected. What does that do to employee morale and retention?
Or how about Search no longer being the endless cash cow due to Bing competing for market share and bidding up the Apple exclusivity deal that Google currently has? Does Google then have to tighten the belt on the money-losing operations, including Google Cloud?
Latency
We don’t mean to rehash too much from last week’s LLM latency discussion, which focused more on hardware, but it’s essential to recognize how these models fit together. Google’s Bard is a smaller model with a lower latency response time. Google has a far superior PaLM model in-house but cannot afford to deploy it.
Even at 2,000ms of latency, 4x that of regular search including internet delays and 20x of processing time, PaLM can only take 60-input tokens (~240 characters) and output 20 tokens (80 characters), and that is when parallelized across 64 TPUv4s, all the while only achieving ~35% utilization.

The big takeaway is that the big LLMs need to be used during the non-time-sensitive portions of the search stack. Furthermore, larger batch sizes can achieve much higher utilization rates in those portions of the stack, albeit with higher latency.
Context Is King
Again, not to rehash last week’s discussion on LLM sequence length, but the key for the user-facing models and future AI silicon is increasing their context window so more of the preceding model or source material can be fed forward through the layers. Scaling sequence length is also very costly in terms of inference costs, which will balloon your cost structure.
As such, there will be many optimizations around this on the real time front. In the crawling and indexing phases, you can maximize context windows to densify the source materials as much as possible to as high of a quality standard as possible.
This then enables smaller models in the real time query portion of the stack to minimize the amount of searching and context window, which in turn reduces latency and improves response times.
LLM Implementations Across The Entire Search Stack
It will also be interesting to see how these technologies applied in the same way by Microsoft as part of some premium enterprise search and conversational AI assistant that scans every document, email, excel sheet, PDF, and instant message across the last 30 years. Google, of course, still has its modules of Android, YouTube, Maps, Shopping, Flights, and Photos which are areas where Microsoft can do very little to compete, so perhaps those keep Google ahead on search regardless of what happens.
Now, we will describe how we envision the new search stack on an operational and infrastructure level. We will go category by category through the stack describing uses for five different types of LLMs and their inference cost structure across the four different layers of the search stack, the crawler, index, query processor, and ad engine. These cost structures will be modeled on Nvidia HGX A100 / H100, which OpenAI and Microsoft will use, and Google’s in-house TPUv4 / TPUv5.
The ad-engine changes are perhaps the most meaningful from a usage model perspective.