




Qualcomm’s AI 100 is a 7nm AI inference acceleration ASIC for the edge. They have been drumming up interest for this product for a while now, but recently at The Linley Conference, they divulged further details. Their main two focuses were performance per watt and latency. These are two pieces in the AI chain where Qualcomm believes they can beat Nvidia and CPU based solutions by a large margin. Furthermore, they seperate themselves from the AI ASIC pack by providing actually good software support. According to SemiAnalysis, this combination of hardware and software has landed Qualcomm a Super 7 Hyperscaler win in addition to a myriad of wins in the edge market.
Qualcomm has stated many times that they are targeting only the inference market and will completely forgo training. They want to be pervasive at edge computing and believe this is the number one target market for inference workloads. Being as close to the source of data generation as possible is how you drive TCO down for any AI solution. Qualcomm envisions the AI 100 also being used in datacenters alongside 5G edge boxes and throughout the IoT infrastructure space.

For the datacenter, natural language processing (NLP) and deep learning recommendation networks (DLRN) are the main areas of focus for Qualcomm. While many startups love to tout image recognition performance, these are generally tiny, unsophisticated models with very few parameters. Much of the explosive growth in AI inference will be coming from huge models in NLP and recommendation engines. Facebook recently gave a sneak peak with their new DLRN which uses 12 trillion parameters, 68.6x more than Deep Mind’s GPT 3. Absolutely enormous models like this will become more common and the leaders in AI will continue to increase model sizes. A inference chip that only works on small networks is useless for inference on massive NLP and DLRNs.
For the Intelligent Edge, Qualcomm is targeting smart cities, retail, safety, manufacturing, and traffic management. This is a broad base of use cases which would generate large amounts of data and require local processing. These use cases generally have low latency requirements which is one of Qualcomm’s largest advantages over GPUs.
For 5G infrastructure, Qualcomm is targeting RAN infrastructure equipment and 5G base stations. There is a whole myriad of computationally intensive algorithms that can be offloaded to neural networks. Secondary carrier prediction, antenna tilting, cell handover, link adaptation, transmission optimization in C-RAN, interference management, and rogue drone detection are all use cases that are actively being pursued. Qualcomm will make a big push for AI 100 in the RAN infrastructure as their base station and antenna offerings become more complete in 2022.
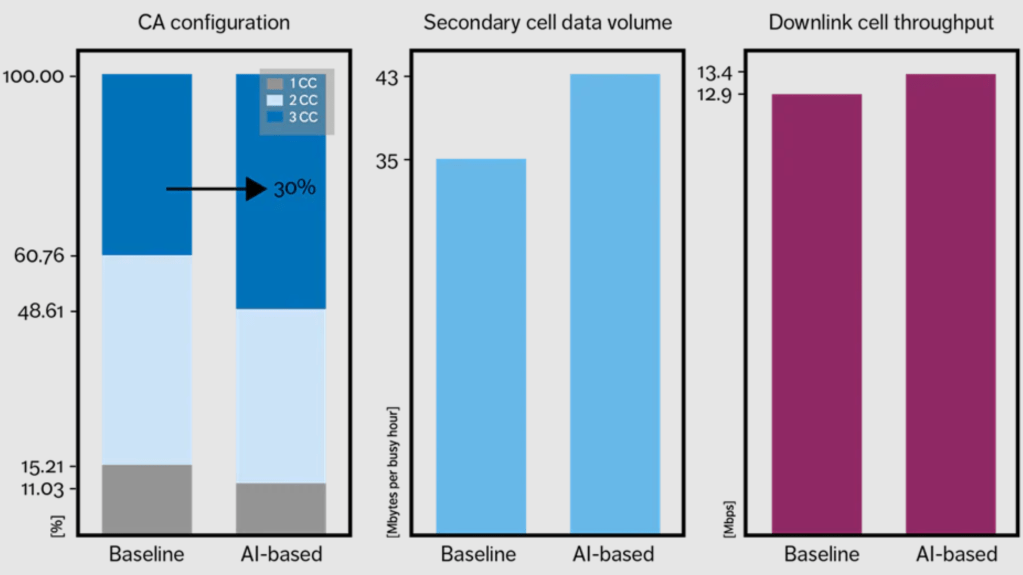
As far as stated performance, Qualcomm has only shown off ResNet50 and SSD-ResNet34 which is quite disappointing given they are talking up performance on large networks. Plenty of firms have demonstrated beating Nvidia on small networks. Qualcomm should be showing performance in larger networks. Thankfully, Qualcomm did tell us that they will show DLRN and NLP models in the upcoming August MLPerf submission.
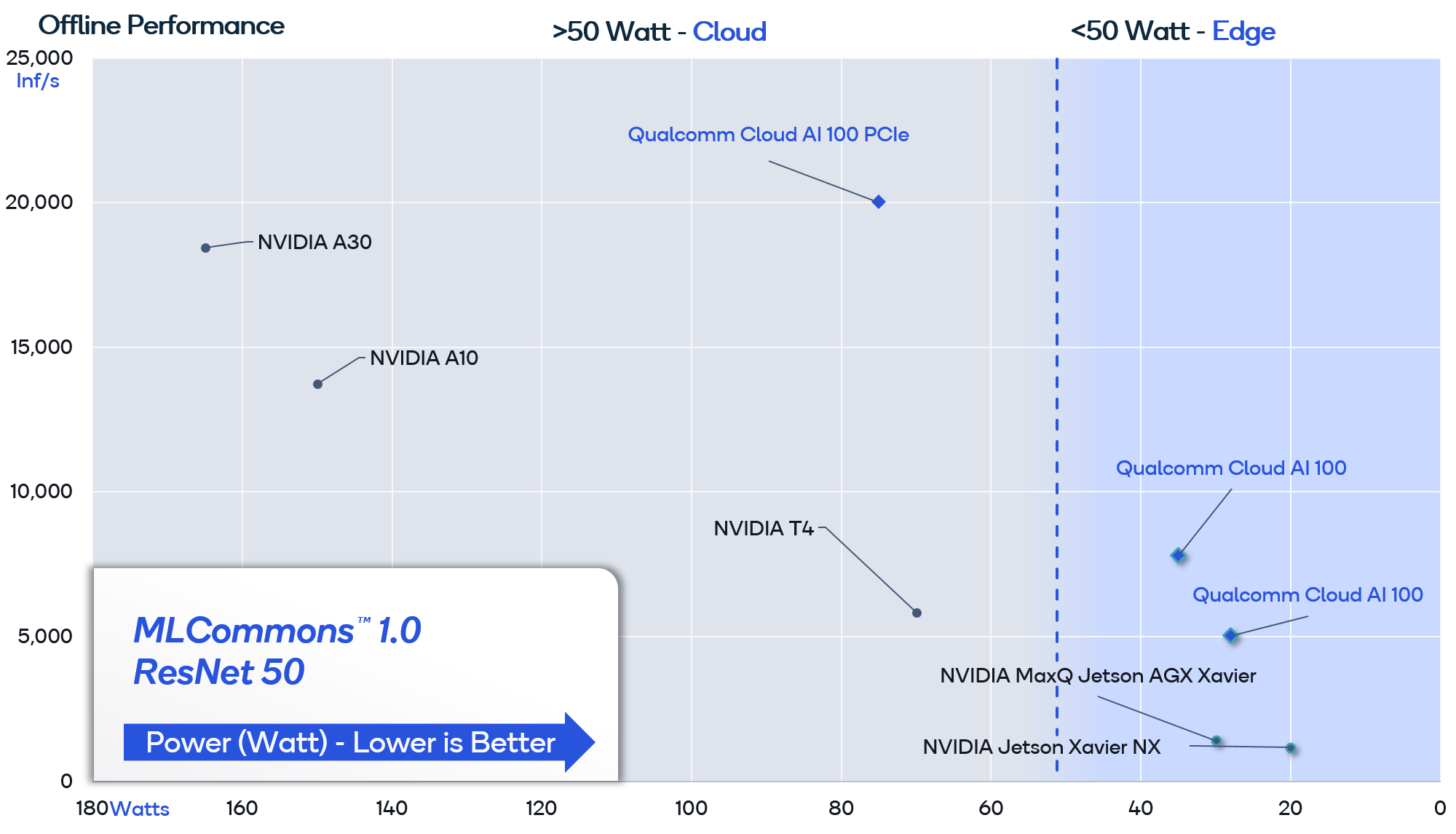
Despite the large gulf in performance per watt marketing and use cases marketing, the MLPerf benchmarks do show the AI 100 is 2x to 4x more efficient than Nvidia’s GPUs. The blue shaded area includes system level power rather than just the ASIC power which is shown in the gray portion of the graph. Qualcomm used a batch size of only 8 where as Nvidia used 32 in their figures. Batch size is an important distinction to make for achieving maximum performance / watt. GPUs require larger batch sizes in order to be utilized effectively. Also not shown on the graph is that each inference completion time is done at a much lower latency.
The Cloud AI 100 is offered in 3 different form factors. They offer drastically different performance, power, and use case targets. The server class is a traditional PCIe half height half-length form factor. There are several other inference accelerators that use this form factor as well as many other PCIe devices in the server space. It is extremely low friction to implement this because it does not require any external power or even a new server design. The other two are dual m.2 cards that align with Open Compute Project standards. These would be more suited for on premise edge applications. Each solution offers differing performance and amounts of memory to better suit its target market. Cloud AI 100 supports a myriad of host solutions from Qualcomm’s own 5G SOCs to AMD and Intel hosts as well. They will also be supporting other Arm vendors server and edge chips as host.
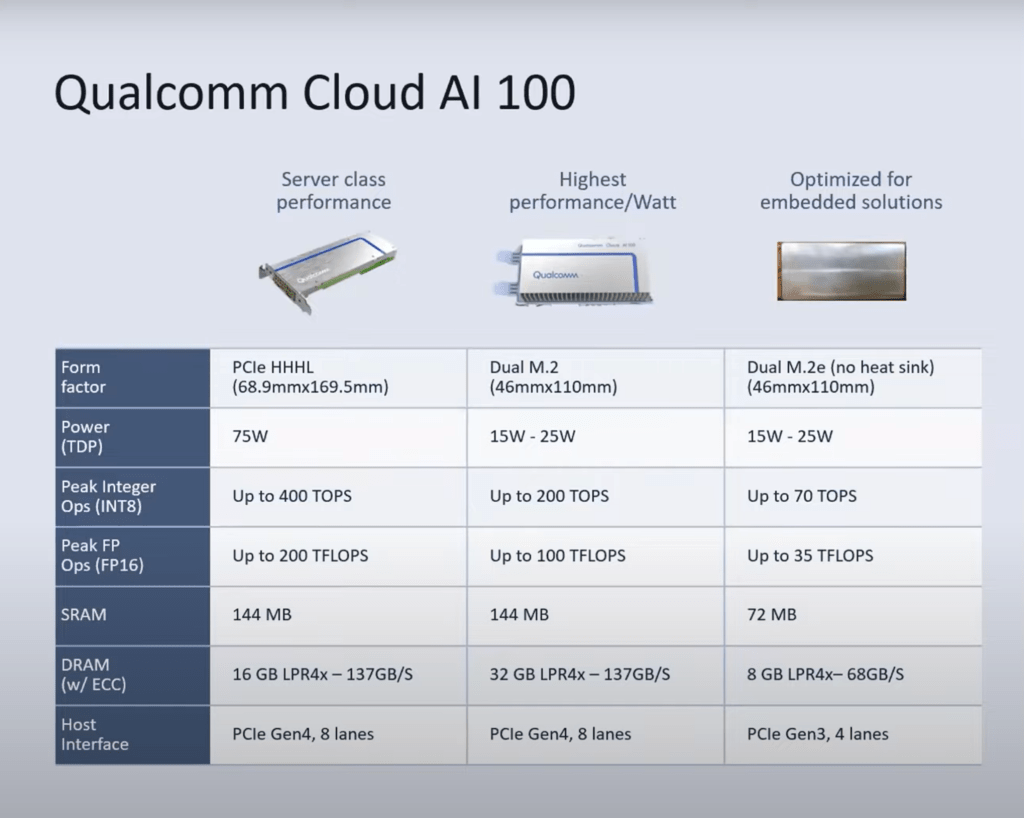
The Cloud AI 100 has a large amount of SRAM on die with 9MB per AI hrdware block. This is a feature that is a very conventional among purpose-built AI accelerators because going out to memory is awfully expensive on power. Qualcomm includes a 256 bit bus with LPDDR4x running at 4266 MT/s. This allows them to strike a fine balance between memory bandwidth and efficiency. This also happens to be the same memory interface Nvidia’s Xavier based product line. Despite similar memory size and bandwidth, Qualcomm achieves far higher performance.

Qualcomm also supports coherent multi-card scaling. The Cloud AI 100 can communicate through PCIe switches without having to go out to the host for communications which saves on power. Many purpose-built AI SOCs for inference cannot scale up in this manner. This is especially advantageous in the DLRNs that are ballooning in size tremendously. Gigabyte demonstrated that with this platform they can deliver 125 Peta-Operations per second.

Powerful AI hardware is not a rarity. Hardware where the software frameworks and architecture are easy and interoperable are significantly more difficult. Qualcomm offers an open stack with support for all major frameworks and runtimes. Qualcomm is following Nvidia’s strategy of supporting models out the box without any tweaks required. They provide an in house, open-source tools for optimization and quantization of models. This is a far departure from Nvidia who has these sorts of tools but keeps them closed and restricted to only their hardware/software solutions.
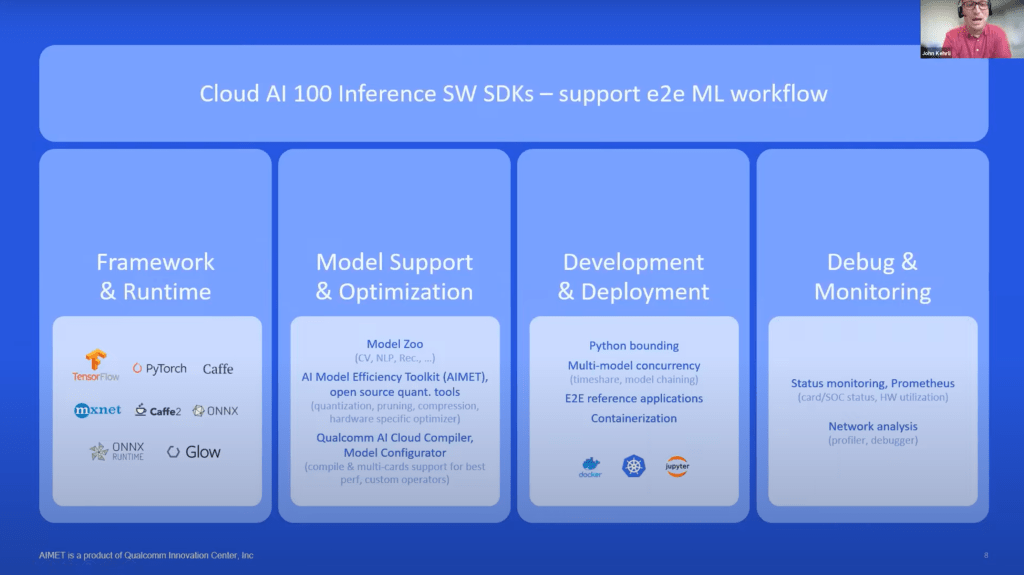
The development pipeline is quite user friendly, only second to Nvidia in the AI space, and the ability to deploy at scale and monitor are best in class for any AI specific ASICs, including Graphcore. The flow for developing on Cloud AI 100 should not be alien to most people within this field. This is a far departure from most other AI specific ASICs which require a custom development pipeline and support for only a fraction of existing frameworks and runtime. Furthermore, they often have little to no support for deployment and load monitoring. Nvidia’s largest advantage of being extremely easy to develop on is being challenged.
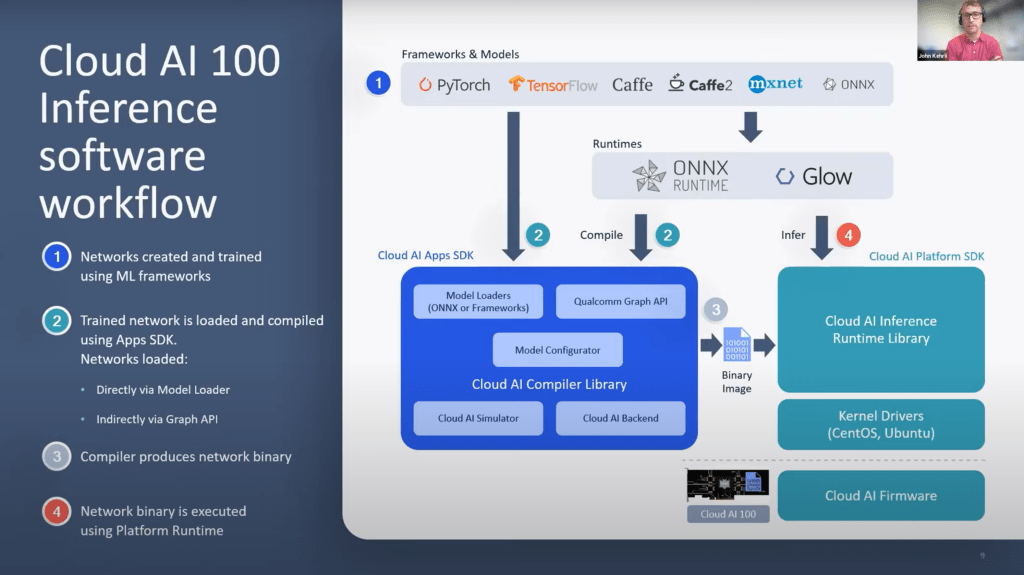
Qualcomm’s solution for inference combines high efficiency with high performance and low latency to make a compelling hardware solution. The clean and well-designed software tools have helped distinguish them from the pack and gain strong market traction starting later this year. Qualcomm seems poised to take large amounts of share in the blooming inference market in DLRNs and NLP. They can leverage their prowess in edge and 5G to offer the best integrated solution for edge AI inference. As this product gets qualified over time and Qualcomm’s ADAS solution is brought up, Cloud AI 100 will make its way into automotive as well. Qualcomm has hit a home run with the Cloud AI 100 because they truly understand the hardware and software co-design that is needed.
This article was originally published on SemiAnalysis on June 17th 2021.
Clients and employees of SemiAnalysis may hold positions in companies referenced in this article.