



SiFive Powers Google TPU, NASA, Tenstorrent, Renesas, Microchip, And More
RISC-V Is The Standard For non-user-facing functions.

SiFive has a portfolio of CPU core IP that has had solid traction in edge, IoT, and AI Chips with significant wins from various companies such as Google, NASA, Tenstorrent, Renesas, Microchip, Kinara, and more. Many dismiss RISC-V for its lack of software ecosystem as a significant roadblock for datacenter and client adoption, but RISC-V is quickly becoming the standard everywhere that isn’t exposed to the OS. For example, Apple’s A15 has more than a dozen Arm-based CPU cores distributed across the die for various non-user-facing functions. SemiAnalysis can confirm that these cores are actively being converted to RISC-V in future generations of hardware.

SiFive has a variety of core IPs, with their E, S, and U series cores having varying levels of success. Despite their deceptive marketing, the P series is not that successful on its high-end P series cores. Today we want to talk about the X280 core, which has rapidly racked up wins. While us nerds are a bit partial to the next generation NASA High-Performance Space Flight CPU, the most significant win is with Google. SiFive announced a collaboration with Google on the TPU here at the AI HW Summit.

The core has relatively high performance despite being in order. The vector pipeline is very wide and implements the full RISC-V Vector 1.0 spec. Furthermore, it has extensions that support bfloat, matrix multiplies, and quantization, allowing it to be optimized for AI. This CPU is performant enough to run as an applications processor in automotive applications or a hypervisor in datacenter applications. Every one of Tenstorrent’s TenSix processor tiles includes X280 CPUs. There is even an automotive version with ISO certifications that can run in lockstep mode, which we believe will be deployed in Toyota cars.
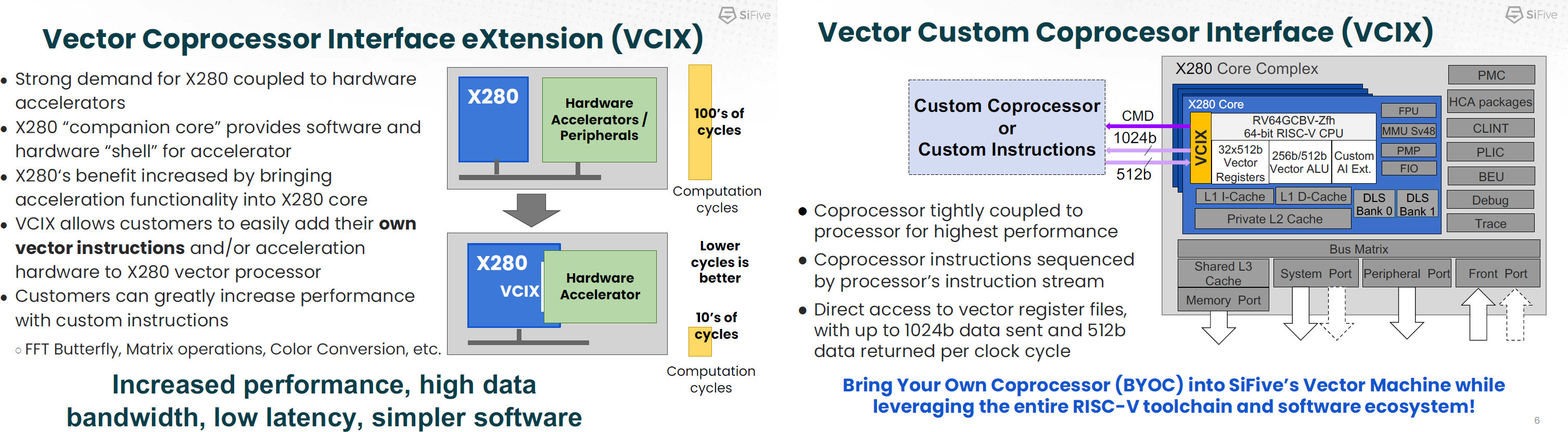
SiFive can offer something Arm cannot, flexibility. Customers can modify their cores by adding hardware accelerators directly into the vector register file. This can be used for extending the X280 core to applications such as DSP, image signal processing, and AI. This is where the Google collaboration comes in.
Google already uses 3rd party ASIC design services with Broadcom for the TPU and VCU. The internal teams focus on what is differentiated to their use case. In the case of the TPU, it is the Matrix Multiply Unit and the Inter-Chip Interconnect. Google is taking a sensible approach to their TPUs by outsourcing redundant work. Instead of building everything from scratch, they will now use X280’s VCIX mode.

Google will utilize the base scalar and vector of X280 in a way that allows push/pop vector instructions. This richer set will enable functions to be overlayed. The programmability is much better as it can now execute python and run conditional routing more easily. Google retains the performance of the MXU but the programmability and well-understood CPU programming model that a RISC-V core offers. The MXUs have a high latency of ~100 cycles, while the CPU can execute scalar and vector code in a few cycles concurrently.
We had the chance to ask Google why they wanted to stick a CPU as part of every one of their accelerator units. This has a significant area impact of around 0.5mm2 per CPU core. Their MMX unit is around 1mm2 per unit, meaning a 50% overhead. The answer was well reasoned and primarily focused on programmability and flexibility.
We could have had a horrible one-off sequencer instead, but do you like to program your machines with low-level assembly?
Cliff Young, Google TPU Architect; MLPerf co-founder
It seems clear that RISC-V will eat the world of non-user-facing cores. We will leave you with this slide that Jim Keller presented.
RISC-V will win the next round. RiscV works. RiscV is open. Risc-V is where innovation is happening. RISC-V will out pace other architectures.
SemiAnalysis is a boutique semiconductor research and consulting firm specializing in the semiconductor supply chain from chemical inputs to fabs to design IP and strategy.