



TSMC’s 3nm Conundrum, Does It Even Make Sense? – N3 & N3E Process Technology & Cost Detailed
Shrinking finally costs more, Moore's Law is now dead in economic terms


A couple of weeks ago, we were able to attend IEDM, where TSMC presented many details about their N3B and N3E, 3nm class process nodes. Furthermore, TSMC announced it would up its capital expenditure in Phoenix, Arizona, with a total of $40 Billion invested in Fab 21 phases 1 and 2. This fab would produce chips in the N5 and N3 families, respectively. This report will cover the process node transition, the excessive costs of TSMC’s most advanced technology, and how it will significantly accelerate changes in the industry towards advanced packaging and chiplets. Furthermore, we will detail the various pitches, features, and SRAM cell sizes for N5, N4, N3B, and N3E.
TSMC 5nm Fab Costs
In early 2018, TSMC announced an investment in a new fab site. This new site would hold its most advanced technology, N5. With Apple and Huawei committing to N5 wafers for 2020, it was the perfect opportunity for a colossal buildout. TSMC stated that their investment in Fab 18 phases 1 through 3 would be over NT$500 billion, or around $17 billion. This site was slated to produce over 80 thousand wafers each month. During the Q1 2020 Earnings Call, TSMC confirmed that N5 was in high-volume production, likely at phase 1.
Although Fab 18 in the Tainan Science Park will remain the primary location for N5 production, TSMC also announced its expansion into the US in Phoenix, Arizona. In mid-2018, TSMC announced that this site would involve a total investment of $12 Billion and a production of 20,000 wafers per month. This fab, when completed, will be the most advanced technology node manufactured by TSMC outside of Taiwan. With TSMC’s N5 capacity being well over 120,000 wafers per month in 2022, this would account for only about 15% of TSMC’s N5 capacity.
At first glance, phases 1 through 3 of the N5 Tainan, Taiwan facilities are 4 times larger, but only 40% more expensive, giving credence to the arguments that it doesn’t make economic sense to build fabs in the United States without significant subsidies. In reality, these numbers are not comparable. TSMC’s number for the US fab includes all total spending from 2021 to 2029. This includes much more than the initial CapEx costs. TSMC’s number for the Taiwan fabs was only the initial buildout, with no other costs.
It should be noted that ~80% of the total cost of a fab during the initial buildout is from equipment. Furthermore, more than ~60% of operational costs are from the material, chemical, tool maintenance, and energy inputs. These costs are mostly the same regardless of the geography a fab is located in (energy does vary).
TSMC 3nm Fab Costs
Fab 18 in the Tainan Science Park is also the primary location for producing the N3 family of nodes. Phases 4 through 6 are dedicated to this family. Fab 12 phases 8 and 9, based in Hsinchu Science Park, will also produce this node. Recently, TSMC announced another investment in Fab 21 Phase 2. This expands its existing fab in Arizona to produce N3 wafers. The new plans for Arizona would increase TSMC’s total spending to $40 billion and increase capacity to 50,000 wafers per month. 20,000 of these will still be N5, and 30,000 will be N3. When completed, N3 capacity would account for ~25% of TSMC’s global capacity for N3.
This would be the first time TSMC has shared a complete cost comparison between fabs of different generations at the same site. With rumors of cost overruns, TSMC’s N5 fab costs may have increased to ~$13B from the original ~$12B. Most likely, these costs are somewhere in the middle of that range.

The total spend per wafer starts per month and increases from 38% to 55%. This ties nicely with the other rumors we have heard for N3E pricing being ~35% more than N5. Contrary to the DigiTimes rumors, the wafer prices are not $20,000. Also, N3B is a decent bit more expensive than N3E.
The story of N3 is a complex one. Initially, N3 was challenging to yield and expensive, more than most customers were willing to pay, given tepid performance, power, and density improvements. It had ~25 EUV layers, almost double that of N5. N3 had many problems surface, culminating in TSMC missing their typical 2-year cycle for major process node releases. N3B, the original N3 entered production in Q4 2022. N3E enters production in mid to late 2023. The most noteworthy change for the general public is that as Moore’s Law slowed, Apple was forced to radically change its chip plans for its products.
In addition to N3 being pushed out from 2022 iPhones to 2023 Pro iPhones, many other customers have also backed away from their original N3 plans. Many rumors exist about Zen 5, Intel GPUs, and some Broadcom custom ASICs. These companies are rumored to have opted to stick with N5 class process nodes or move on to the relaxed N3E process. The original N3 is called N3B by most and will not ramp much beyond Apple. We will dive into the technical differences later in this report, but N3E shares the same SRAM bit-cell size as N5 class process nodes and reduces the number of EUV exposures.

The density improvements are, at best, slightly better than the wafer cost increases. With the FinFlex 2-1 implementation, density improvements are ~56%, with a ~35% cost increase. This results in an ~15% cost per transistor improvement, the weakest ever scaling for a major process technology in 50+ years.
The other implementations are either flat on cost per transistor or even negative, but come with greater per-transistor speed improvements. Note that the above improvements, gen-on-gen, are measured with the Arm Cortex A72. The density improvement will vary based on what IP is being implemented.
Most chip designs will not achieve the 56% density improvement, but instead a much lower ~30%. This would imply a cost per transistor increase, but companies are adjusting designs to ensure that does not happen. This will be explained in the process technology section.
3nm Implementation Costs
The decision to move to 3nm or stay within the N5 family becomes even more tricky when the cost of implementing a chip on the most advanced process technology becomes even higher.

We explained this issue in detail above, but the fixed costs of implementing a product in the newest process technology are getting so large that it represents a massive risk for companies. Delays get more tricky, respins get more costly, and worst of all, the volume required to achieve a cost-per-transistor improvement becomes higher and higher.
For that reason, many firms will stick with N5 class process nodes for a long time to come. Many others will only transfer compute chiplets to the N3 class while keeping all other IPs, such as SRAM and analog on older process technologies. TSMC N3 will result in an explosion of chiplets and advanced packaging.
Before we get into the N3 process details, we wanted to detail the N5 family, as it is a true testament to how amazing TSMC is. It isn’t one process node that is iterated on, but many concurrent flavors and modifications that best suit each different type of customer’s needs.
5nm Process Family Technology Detailed
Part of what TSMC’s N5 family consists of: N5, N5P, N5A, N4, N4P and N4X. In addition to those announced variants, we expect TSMC to release RF-optimized and leakage-optimized versions in the next couple of years. With all these variants, TSMC is looking to extend the life of the process technology and push more of its customers to the N4 nodes, partly due to their lower cost of production and lower fixed costs for customers. N4 is the latest node in high-volume production, implemented in the MediaTek Dimensity 9200, Qualcomm Snapdragon 8 Gen 2, and Apple A16.
N5 is a marvel of engineering and was firmly the most advanced node at its launch. TSMC announced that it would have a 1.84x higher logic density, provide a 15% increase in performance at the same power and reduce power consumption by 30% at the same performance. While countless chips certainly enjoyed improvements in performance and power, the stated density gains never seemed to be achieved.
As Angstronomics covered recently, this was because TSMC lied. The gains in logic density were closer to 52%. While TSMC may have lied about its density, it is still clear that TSMC N5 is the best node in high-volume production.
N5 has a fin pitch of 28nm, only slightly behind that of Samsung 5LPE, and a contacted gate pitch of 51nm, only slightly behind that of Intel 4. Through the novel method of continuous diffusion, they managed to reduce the cell width. We will detail this in a future article on scaling boosters.
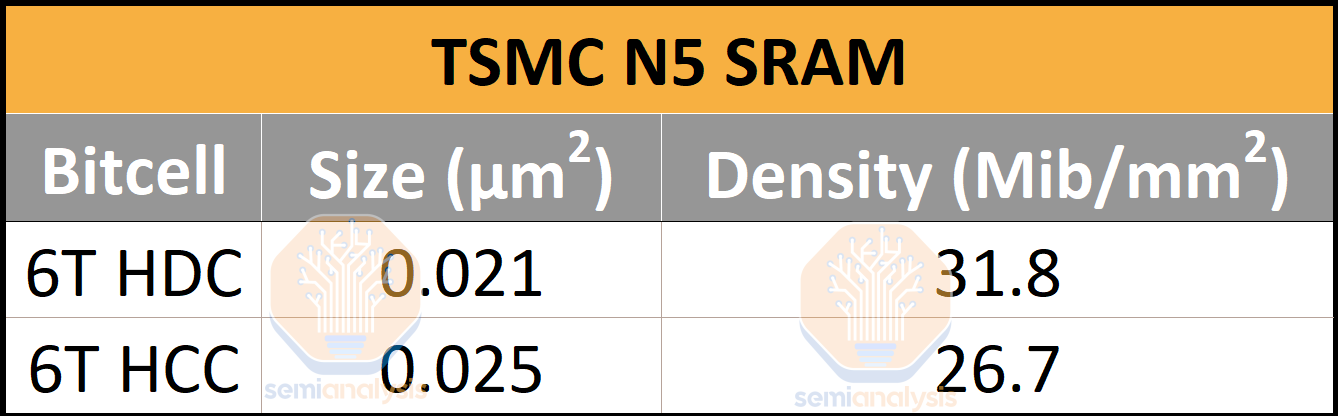
N5 has a minimum metal pitch on M0 of 28nm, a 30% reduction over N7. This will help to reduce bottlenecks that may be caused by signal and power routing. With an M2 metal pitch of 35nm, TSMC has a 6-track standard cell, the densest possible, using FinFETs with 2 PMOS fins and 2 NMOS fins. N5 also has the smallest 6T high-density SRAM bit-cell with a size of 0.021 μm2, lower than Intel 4’s 0.0240 μm2 and Samsung 4LPE’s 0.0262 μm2 bit-cells. TSMC’s 6T high current SRAM bit-cell is also incredibly tiny at 0.025 μm2, the third densest to date.
N5P is a process optimization of N5. Through enhancements of the FEOL and MOL of the process, TSMC eked out 7% higher performance and 15% lower power. While this may not seem like much, the benefit is that this process optimization is IP-compatible with N5. Any N5 designs can easily be ported to N5P and see these gains. With the soaring fixed costs of semiconductor design, the impact of this cannot be understated.

N4 is another process optimization of N5, but it comes with a small design shrink. This is also referred to as a “nodelet.” Through optimizations in the standard cell library, a small optical shrink, and changes in design rules, N4 achieves better area efficiency. N4 also reduces the number of masks and process complexity. This enables TSMC to produce N4 at a lower cost than N5 per wafer.
There was a rumor started by Nikkei Asia that the Apple A16 cost 2x as much to fab, but that is completely false. Much like N5P, power and performance characteristics were improved through improvements in the FEOL and MOL.


Like TSMC’s other nodelet, N6, N4 offers two approaches for migration from an existing N5 design. Both have their trade-offs. First is the RTO or re-tapeout, which involves using the same design rules as N5. This is cheaper, requires less engineering, and provides less of the benefits of N4. This is how MediaTek was able to release the Dimensity 9000 on “N4” so soon after it reached risk production.
Next up is the NTO or new tapeout, this requires logic blocks to be reimplemented using the latest libraries provided by N4 and more optimizations. This requires more engineering but provides more benefits, including a minor area shrink.
In late 2021, TSMC announced N4P, a process optimization of N4. Through further improvements in the FEOL and MOL, TSMC increased performance by another 6% over N4 and reduced power consumption by 22% over N5.
Now onto the specialty technologies; N5A is based on TSMC’s N5 process. This node isn’t particularly unique technologically. However, it is certified for all the standards automotive companies look for in using a process node. It is optimized to survive prolonged periods of time in vehicles, periods of 10 or 20 years, without degrading.
N4X is TSMC’s first HPC-optimized process technology. N4X has optimizations for high voltage devices at over 1.2V, with 4% higher performance than N4P. The FEOL presents improvements in the fins to allow for higher currents, voltages, and increased frequency. The metal stack has been engineered to improve power delivery and signal integrity in these high-performance devices by reducing resistance and parasitic capacitance. The metal stack also features improved Metal-in-Metal capacitors to provide more robust power delivery by reducing voltage droop and increasing performance by a further 2-3%.
To achieve such high frequencies, it is likely that some design rules have been relaxed, but this is likely not an issue as high-performance devices are even more limited by their metal stacks and cannot make use of the density regardless. There are also some concessions regarding the leakage which had to be made to enable higher performance. Most semiconductor companies will not use this node as they prefer lower power/leakage, but N4X is a strong contender for some highest-performance applications.
Now, we shall discuss the critical pitches of the N5 family of nodes and exclusively detail the pitches of TSMC’s N4 node. N5’s high density (HD) library has a fin pitch of 28nm, with 8 diffusion lines for a cell height of 210nm. The contacted gate pitch (CGP) is 51nm. N5’s high performance (HP) library has the same pitch, but adds 2 diffusion lines for a cell height of 280nm. The high-performance library also relaxes the CGP slightly to 57nm, enabling higher performance. As stated by TSMC, N4 offers a 6% area reduction through optical shrinks. To achieve this, the HD and HP libraries’ cell height has shrunk to 206nm and 274nm, respectively. Moreover, the CGP has shrunk to 49nm and 55nm.

N5 offers a pitch of 28nm for its lowest metal layer, the smallest in production. This is also the minimum metal pitch for the node. It also offers a metal 2 pitch of 35nm, the smallest in production.
As we mentioned, N5 has the densest bit-cell in production in each 6T HD and HP bit-cell category. With an assist circuitry overhead of 30%, this lands their HD SRAM density at 31.8 Mib/mm2 and their HP SRAM Density at 26.7 Mib/mm2. Although N4 did not bring further reductions in the size of the SRAM bit-cell, TSMC remains in the lead.
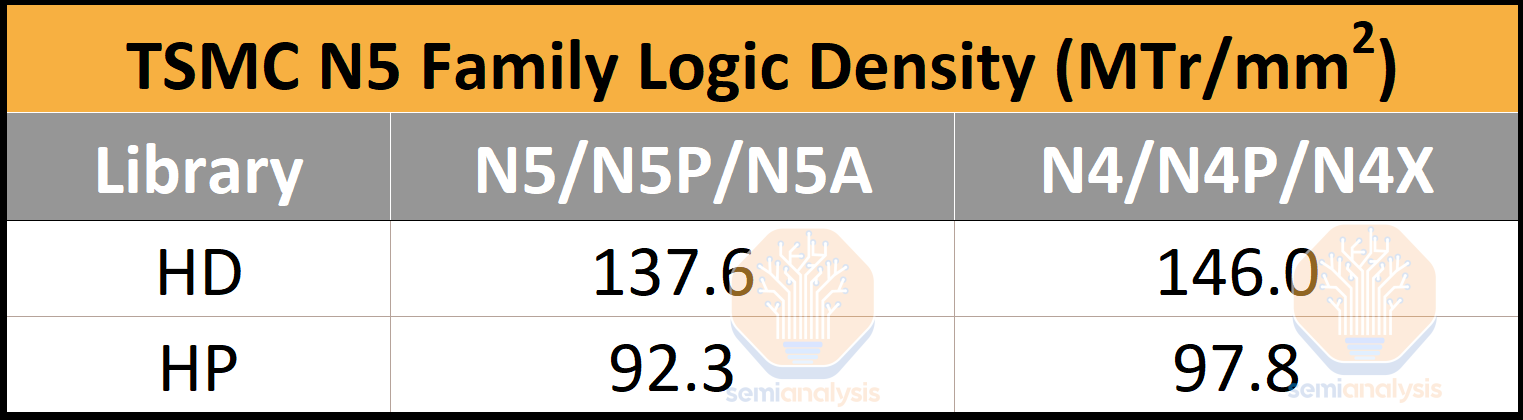
Now, onto the main attraction, logic density. While this may be the most attention-grabbing number, it does not describe a node on its own. Every other characteristic must be considered, from its SRAM bit-cell to power and performance. These metrics are calculated with the Bohr formula, which assigns a weight of 60% to small, undense NAND2 cells and 40% to large, but dense Scan Flip-Flop cells. TSMC leads in this metric, though less than in other factors.
While the density of its HD library is the highest in production, the density of its HP library lags Intel 4’s HP. To be clear, Intel 4 is “manufacturing-ready,” according to Intel, but true high-volume manufacturing is still a couple of quarters away. Nevertheless, density is one of the most enticing reasons to use TSMC’s N5 family of nodes.
TSMC’s N5 family is an excellent set of nodes, and these metrics alone do not do it justice. Its combination of power, performance, area, ease of use, IP ecosystem, and cost are unmatched.
N3 Technology Nodes
The N3 family of nodes includes N3B, N3E, N3P, N3X and N3S. Many of these are nodelets optimized for specific purposes but with a twist. N3B, the original N3, is not related to N3E. Instead of being a nodelet, one should consider it an entirely different node.
At IEDM 2022, TSMC revealed some aspects of N3B. N3B features a CGP of 45nm, 0.88X scaling versus N5. TSMC also implemented self-aligned contacts, which allows greater scaling of the CGP. We will detail this, as well as other DTCO scaling, in a future series. TSMC also demonstrated a 6-transistor high-density SRAM bit-cell of 0.0199 μm2. This is only a 5% shrink, which bodes poorly for SRAM scaling into the future.
In recent years, chip designers have leaned heavily on SRAM to improve performance. The death of SRAM scaling takes away a big lever for increasing performance and will increase the importance of architecture in improving power and performance characteristics.

Compared to N5, TSMC initially stated that N3 would increase performance by about 12% at the same power and a power reduction of 27% at the same performance. This would have come with a 1.2× SRAM density and 1.1× analog density.
The high-density bit-cell disclosed at IEDM only improves SRAM density by about 5%, a far cry from the 20% initially stated.
Can anyone explain why TSMC is being disingenuous again………
During IEDM, TSMC revealed that N3B has a CGP of 45nm, the densest revealed thus far. This is ahead of Intel 4’s 50nm CGP, Samsung 4LPP’s 54nm CGP and TSMC N5’s 51nm CGP.
While the increase in logic density is undoubtedly promising, the low SRAM density gain means that SRAM-heavy designs will likely experience significant cost increases. N3B also has poor yields and metal stack performance. For these reasons, N3B will not be the primary node for TSMC.

With N3B failing to reach TSMC’s targets for performance, power, and yield, N3E was developed. Its purpose was to fix the shortcomings of N3B. The first significant change is a slight relaxation of the metal pitches. Instead of using multi-patterning EUV on the contacts, V1, V2, M0, M1, and M2 metal layers, TSMC backed off and switched to single patterning.
Furthermore, three critical layers requiring EUV double patterning in previous generation are replaced by single EUV patterning, which reduces process complexity, intrinsic cost and cycle time.
TSMC at IEDM
The number of EUV layers goes from 25 in N3B to 19 on N3E. This was achieved while keeping the power and performance figures similar. Logic density also shrunk slightly. Moreover, with a standard monolithic chip (50% Logic + 30% SRAM + 20% Analog), density only increases by 1.3x. This is effectively flat on cost per transistor for the typical monolithic chip designs, with higher development costs.
During IEDM, TSMC revealed that N3E had a bit-cell size of 0.021 μm2, precisely the same as N5. This is a devastating blow to SRAM. TSMC backed off of the SRAM cell size versus N3B due to yields.
The 256Mb HC/HD SRAM macros and product-like logic test chip have consistently demonstrated healthier defect density than our previous generation
TSMC
N3E is doing much better than N3B and will be in high-volume production in the middle of next year. For those keeping track, that's over 3 years from the introduction of N5. This is the node that AMD, Nvidia, Broadcom, Qualcomm, MediaTek, Marvell, and many other companies will eventually be using N3E for their leading edge.
Unlike the previous nodelets that TSMC has launched for its N7 and N5 family of nodes, N3E is not IP-compatible with N3B IP. This means that IP blocks have to be reimplemented. As such, many companies, such as GUC, have chosen only to implement their IP on the more long-lasting N3E node.
N3P will be the follow-up node to N3E. It is much like N5P and provides minor performance and power gains through optimizations while maintaining IP compatibility. N3X is similar to N4X and is optimized for very high performance. The power, performance targets, and timeline have yet to be announced thus far.
N3S is the final disclosed variant, stated to be a density-optimized node. Not much is much is currently know, but there are some rumors. Angstronomics suggests that this may be a single-fin library, which allows TSMC to shrink the cell height further. With the limiting factor of the metal stack, this is likely of limited use, but designs will use it if they can. N3S may even implement a backside power delivery network to alleviate many metal stack concerns, although that is not confirmed.
As TSMC’s last FinFET node, N3E and its successors have the opportunity to gain a similar status as that of N28, one of TSMC’s most successful nodes. This will be a difficult task, given its tumultuous history, but TSMC has proven its abilities many times over, especially in its ecosystem.
Now, we shall compare N3B and N3E to N5. The DTCO and shrink changes are very interesting.