

CXL Deep Dive – Future of Composable Server Architecture and Heterogeneous Compute, Products From 20 Firms, Overview of 3.0 Standard
Future CXL Products From 20 Firms Reviewed

Traction for the Compute Express Link (CXL) is reaching a critical mass as every major semiconductor and datacenter company has joined the standard with a wave of 1st generation devices nearing release. The 3rd generation of the Compute Express Link (CXL) specification was just announced, and it brings about some significant changes that were missing in prior versions of this standard. This article discusses composable server architecture, heterogeneous compute, and versions 1, 2, and 3 of the CXL standard.
In the second half of the report, we will be conducting a status update discussing upcoming products that will utilize CXL from 20 different semiconductor companies, including market opportunity, timing, and capabilities. One of the best semiconductor investors we know once said that accurately understanding and framing the impact of CXL on the datacenter will be the most important source of alpha within semis, and we agree. The products from these 20 companies will include CPUs, GPUs, accelerators, switches, NICs, DPUs, IPUs, co-packaged optics, memory expanders, memory poolers, and memory sharers.
The companies we will be discussing are Intel, AMD, Nvidia, Ayar Labs, HPE, Microsoft, Meta, Google, Alibaba, Ampere Computing, Samsung, SK Hynix, Micron, Rambus, Marvell, Astera Labs, Microchip, Montage Technology, Broadcom, and Xconn. There are more than 200 members of the CXL Consortium, but these are the companies we believe have the most impactful products and IP.
In the past, datacenter chips were primarily about building better CPU cores with faster memory. Servers from a decade ago mostly look the same as servers from today. Over the last decade, the battle has changed with the advent of scale-out and cloud computing. The fastest core isn’t the priority. The focal point is how cost-effectively one can deliver total compute performance and hook it all together. In our advanced packaging series, we dug into the slowdown of Moore law and the impacts of the death of semiconductor cost scaling.
These trends all point to a tide of specialization of computational resources. One of the ultimate examples of the law of diminishing return is that each incremental transistor spent on general-purpose CPU performance delivers incrementally less performance. Heterogeneous compute reigns supreme as specialized ASICs can provide more than 10x the performance in specific tasks with fewer transistors.
Designing specific chips with the exact computational resources for each workload is prohibitively expensive. This idea was examined in our article titled “The Dark Side Of The Semiconductor Design Renaissance.” In short, the fixed costs of designing chips are soaring due to photomask set costs, verification, and validation.
Instead of designing chips for entire workloads, it would be far more cost-effective to design chips for classes of computation and connect them in whatever configuration the specific workload desires.
It may prove to be more economical to build large systems out of smaller functions, which are separately packaged and interconnected. The availability of large functions, combined with functional design and construction, should allow the manufacturer of large systems to design and construct a considerable variety of equipment both rapidly and economically.
Dr. Gordon Moore In The Original Paper Which Predicted “Moore’s Law” – “Cramming more components onto integrated circuits” – 1965
The change in how systems are built moves the unit of compute up from a single chip or server to the entire datacenter.
The datacenter is the new unit of computing.
Jensen Huang
Connecting chips within a server has typically been done with PCI Express. The biggest drawback is that this standard lacked cache coherency and memory coherence. A non-technical analogy for these two concepts is if you think about servers like a post office. Letters are coming in asynchronously, often days after new information has made the letter containing the original information obsolete. Coherency helps manage and equalize this.
With PCI Express, the overhead for communicating between different devices was relatively high from a performance and software perspective. Furthermore, connecting multiple servers typically means using Ethernet or InfiniBand. These methods of communication share all the same issues and have much worse latency and lower bandwidth.
In 2018, IBM and Nvidia brought a solution to the drawbacks of PCI Express with NVLink into the then world’s fastest supercomputer, Summit. AMD has a similar proprietary solution in the Frontier supercomputer called Infinity Fabric. No industry ecosystem could develop around these proprietary protocols. CCIX cropped up as a potential industry standard in the mid-2010s, but it never really took off because it lacked the critical mass of industry support despite having backing from AMD, Xilinx, Huawei, Arm, and Ampere Computing.
Intel had over 90% CPU market share, so no solution would fly without their buy-in. Intel was working on their own standard, and they donated their proprietary specification as Compute Express Link (CXL) 1.0 to the newly formed CXL Consortium in 2019. This standard came with simultaneous buy-in from most of the biggest buyers in the semiconductor industry. CXL piggybacks off the existing ecosystem of PCIe 5.0 by using its physical and electrical layer, but with the improved protocol layer, which adds coherence and low-latency mode for load-store memory transactions.
CXL makes the transition to heterogeneous compute possible due to establishing an industry-standard protocol that most major players in the industry support. Now the industry has a standard interconnect for connecting these various chips together.
AMD’s Genoa and Intel’s Sapphire Rapids will support CXL 1.1 in late 2022/early 2023. CXL 1.1 comes with 3 buckets of support, CXL.io, CXL.cache, and CXL.mem. CXL.io can be thought of as a similar but improved version of standard PCIe. CXL.cache allows a CXL device to coherently access and cache a host CPU’s memory. CXL.mem allows the host CPU to access the device’s memory coherently. More detailed explanations are included in the bullet points below. Most CXL devices will use a combination of CXL.io, CXL.cache, and CXL.mem
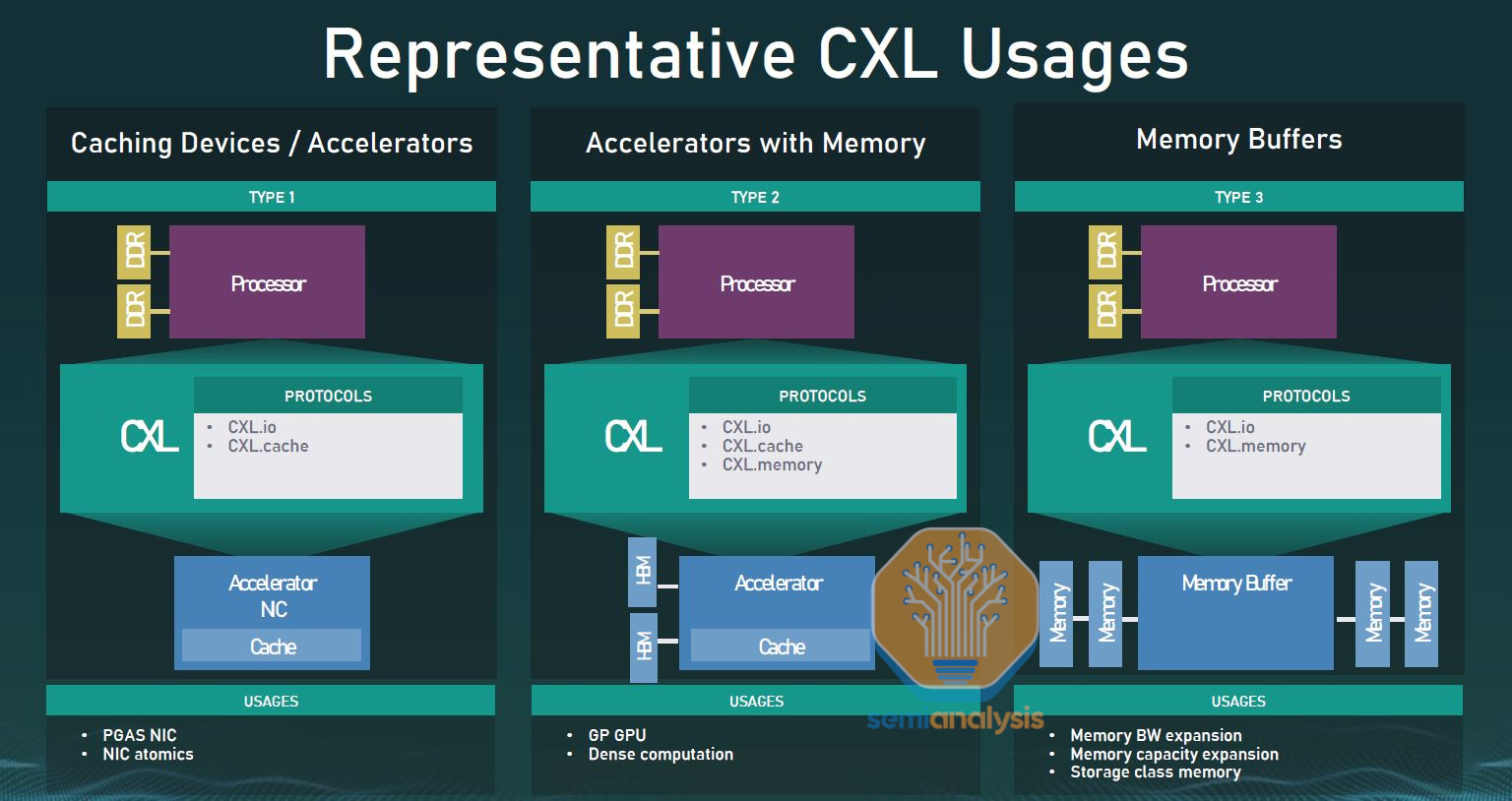
· CXL.io is the protocol used for initialization, link-up, device discovery and enumeration, and register access. It provides an interface for I/O devices and is similar to PCIe Gen5. It also is mandatory that CXL devices support CXL.io.
· CXL.cache is the protocol that defines interactions between a Host (usually a CPU) and Device (such as a CXL memory module or accelerator. This allows attached CXL Devices to cache Host memory with low latency due to safe use of their local copy. Think of this as a GPU directly caching data from the CPU’s memory.
· CXL.memory / CXL.mem is the protocol that provides a Host processor (usually a CPU) with direct access to Device-attached memory using load/ store commands. Think of this as the CPU using a dedicated storage-class memory Device or using the memory found on a GPU/ accelerator Device.
So far, we have mostly talked about heterogeneous compute, but the real kicker for CXL will be regarding memory. In the past, we discussed this in our article explaining Marvell’s purchase of Tanzanite Silicon and competition in memory accelerators from Astera Labs and Rambus. We expanded on this idea in our dive into Microsoft’s memory pooling solution. We will do a more detailed overview heredirect-attached.

Datacenters have a massive memory problem. Core counts have grown rapidly since 2012, but the memory bandwidth per core and capacity has not increased commensurately. The memory bandwidth per core has fallen somewhat since 2012, and this trend will continue in the future. Furthermore, there is a massive gap in latency and cost between direct-attached DRAM and SSDs. Lastly, the costly memory resources often have poor utilization, which is a killer. Low utilization rates are a significant drag for any capital-intensive industry, and the data center business is one of the most capital-intensive industries in the world.
Microsoft states that 50% of total server costs are from DRAM alone. Despite the massive DRAM cost, up to 25% of their DRAM memory is stranded! In simple terms, 12.5% of Microsoft Azure’s total server costs are doing nothing.
Imagine if this memory could instead live on a connected network and be dynamically assigned to VMs across multiple CPUs and servers, rather than sitting at each CPU. Memory bandwidth could grow and shrink based on the demands of a workload. This would massively increase utilization rates.
This concept isn’t limited only to memory but also to all forms of compute and networking. Composable server architectures are when servers are broken apart into their various components and placed in groups where these resources can be dynamically assigned to workloads on the fly.
The datacenter rack becomes the unit of compute. Customers could choose an arbitrary number of cores, memory, and AI processing performance for their specific task. Or better yet, the cloud service provider such as Google, Microsoft, Amazon, etc could arbitrarily assign resources to their customers based on the type of workload they are running and charge the customer only based on what they are using.
This vision is the holy grail of server design and cloud computing. There are many complex engineering problems associated with this; many centered around the latency and cost of building the network to hook everything up. These must be critically examined, but the protocol must come first, which is what CXL 2.0 and 3.0 bring.

The headline features for CXL 2.0 are that memory pooling and switching are supported. CXL switches can connect multiple hosts and devices, allowing the number of devices connected on a CXL network to grow significantly. The new multiple logical devices feature allows numerous hosts and devices to all be linked and communicate with each other without the master-slave relationship that has been mandated historically. The network of resources will be orchestrated by the fabric manager, which is a standard API to control and manage this system. Fine-grained resource allocation, hot plug, and dynamic capacity expansion allow hardware to be dynamically assigned and shifted between various hosts without any restarts.

A picture is worth a thousand words, so let’s discuss the image above. Multiple hosts can be connected to switches. The switch is then connected to various devices, SLD (single logical device) or MLD (multiple logical devices). MLD are designed to couple to multiple hosts for memory pooling.
The MLDs show up as multiple SLDs. This allows them to pool the memory between hosts or even pool accelerator compute resources. The FM (fabric manager) is in the control plane. It is the orchestrator, allocating memory and devices. The fabric manager can sit on a separate chip or in the switch; it doesn’t need to be high performance as it never touches the data plane. This can also be achieved without a switch if that CXL device is multi-headed and connects to the root port of multiple hosts.

Tying it all together, Microsoft demonstrated the potential to reduce DRAM deployed by 10% and save 5% on total server costs by pooling DRAM. This was on the first-generation CXL solution without utilizing CXL switches.
CXL 3.0 brings about even more improvements that help extend the ability to create heterogeneous composable server architectures. The main focus is extending CXL from the scale of servers to the scale of a rack. This is achieved by moving from a host-device model to making CPUs just another device on the network.
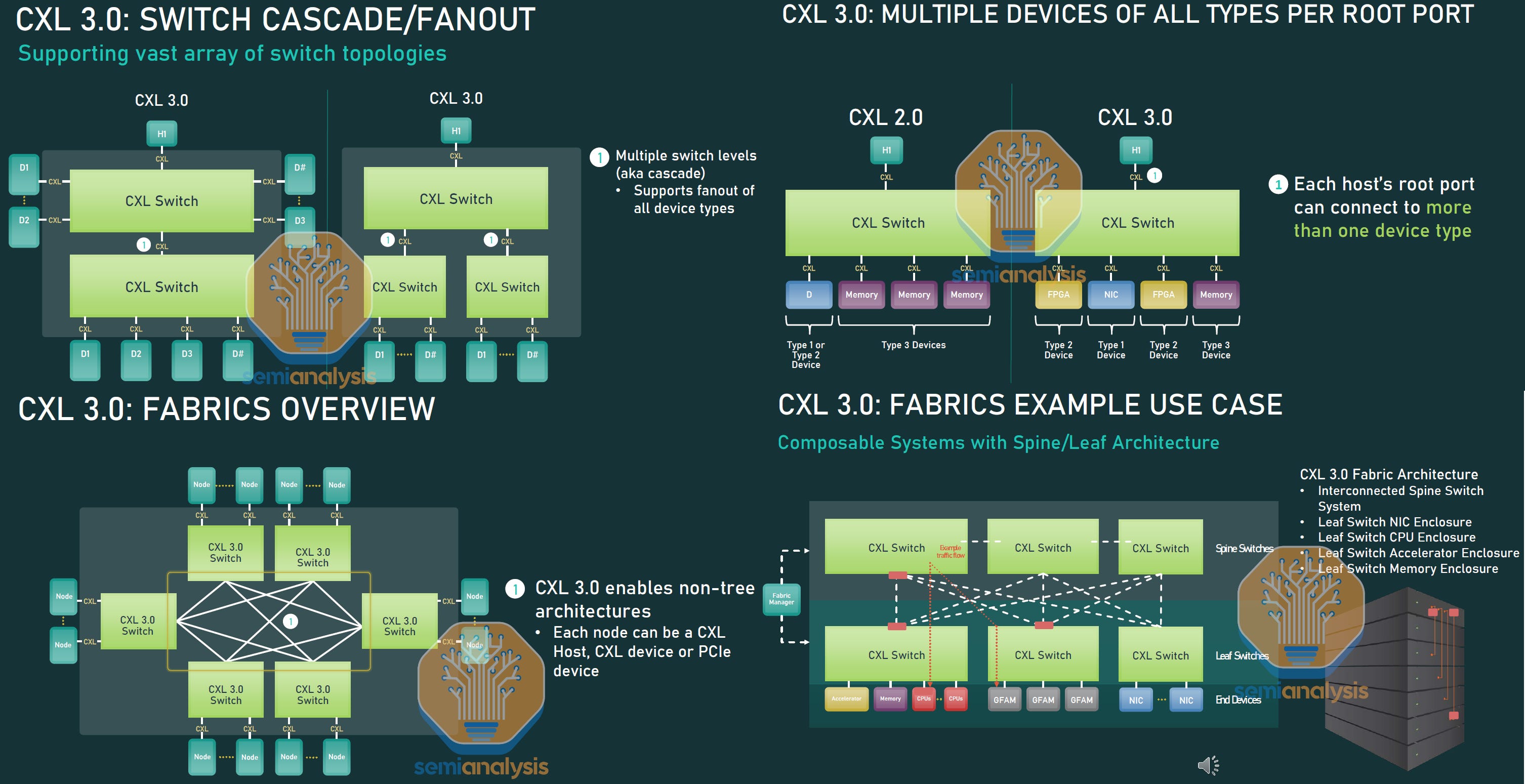
CXL switches now can support an array of topologies. Previously in CXL 2.0, only fan-out with CXL.mem devices was possible. A rack or many racks of servers can now be networked with leaf and spine or all to all topologies. The theoretical limit of devices/hosts/switches/switch ports is 4,096 with CXL 3.0. These changes dramatically expand the potential size of a CXL network from a few servers to many racks of servers.
In addition, multiple devices of all types can sit on a single root port of CXL from a host. This was previously a major limitation as a single root port could only address a single device type. If a host connected to a switch with a single root port of CXL, that host could only access one type of device sitting off the switch.

The most important changes in CXL 3.0 are memory sharing and device-to-device communications. Hosts CPUs and devices can now work together on the same datasets without needlessly shuffling and duplicating data. One example is a common AI workload like the multi-billion parameter deep learning recommendation systems employed by titans like Google and Meta. The same model data is duplicated across many servers. Users’ requests come in, and inference operations are run. If CXL 3.0 memory sharing existed, a large AI model could live in a few central memory devices with many other devices accessing it. This model can be constantly trained with live user data, and updates can be pushed across CXL switch networks. This could reduce DRAM costs by as much as an order of magnitude and improve performance.
The areas in which memory sharing can improve performance and economics are almost limitless. 1st generation memory pooling can reduce total dram requirements by 10%. Lower latency memory pooling could bring the savings in a multi-tenant cloud to ~23%. Memory sharing could reduce DRAM requirements by more than 35%. These savings represent billions of dollars in datacenter DRAM spend annually.
Uses of CXL
In the second half of this report, let’s talk about products, timing, and strategy from 20 firms on CXL, including switches, NICs, DPUs, IPUs, co-packaged optics, memory expanders, memory poolers, memory sharers, CPUs, GPUs, and accelerators.
The firms being discussed in the subscriber-only section are Intel, AMD, Nvidia, Ayar Labs, HPE, Microsoft, Meta, Google, Alibaba, Ampere Computing, Samsung, SK Hynix, Micron, Rambus, Marvell, Astera Labs, Microchip, Montage Technology, Broadcom, and Xconn. In this section, we mainly discuss off-package capabilities, but on-package will be addressed separately in a later piece about UCIe.